Elasticsearch分词器(一)
“分词”是在Elasticsearch中进行存储和全文搜索的一个很重要的部分,因为只有选择合适的分词器才能更高效地进行全文搜索。Elasticserach中提供了多种内置的分词器,针对不同的场景可以使用不同的分词器。这些分词器只对text类型字段有效,而对keyword类型字段无效。
simple分词器
simple分词器是对字母文本进行分词拆分,并将分词后的内容转换成小写格式。范例如下:
POST _analyze
{
"analyzer": "simple",
"text": "Elasticsearch is a search engine based on the Lucene library"
}
分词分析后的结果如下:
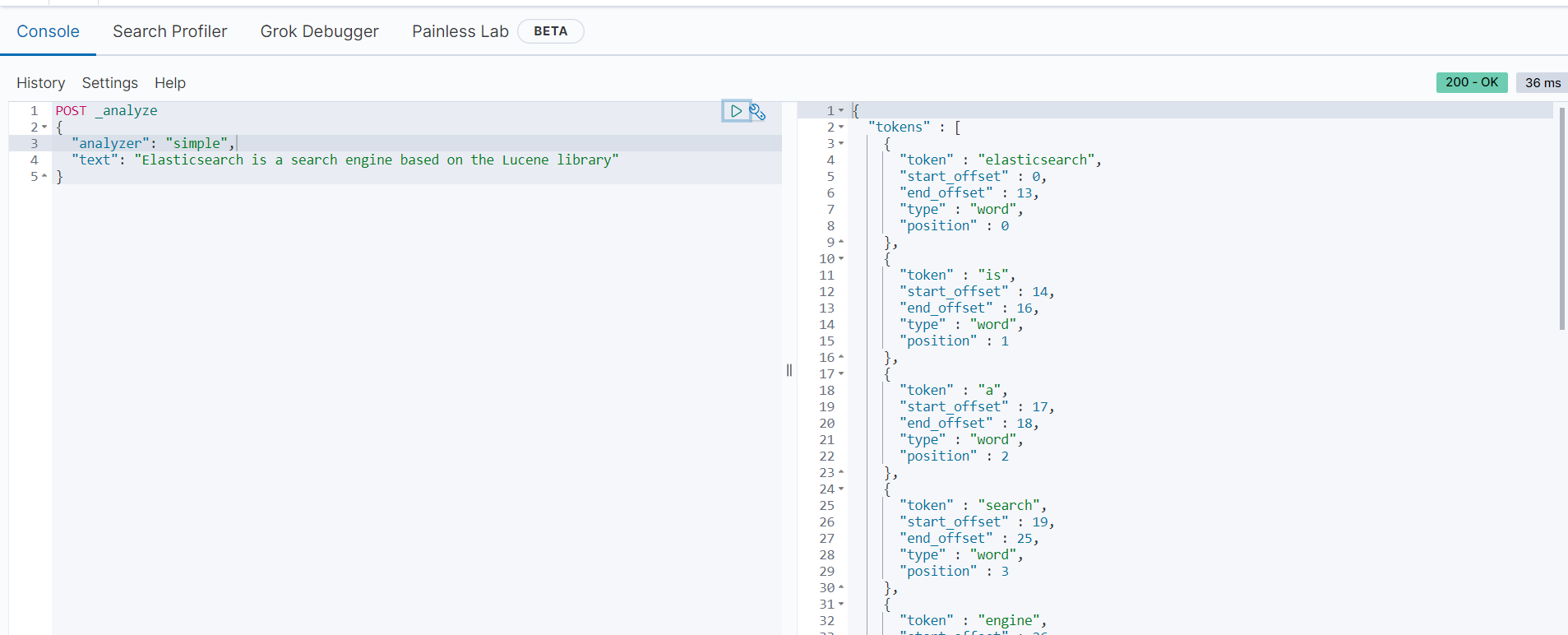
可以看到“Elasticsearch is a search engine based on the Lucene library”被分成了14个关键字并且所有字母都是小写的,分词之后的单词如下:
["elasticsearch", "is", "a", "search", "engine", "based", "on", "the", "lucene", "library"]
simple_pattern分词器
Elasticsearch还提供了根据正则表达式进行分词的分词器(simple_pattern分词器),范例如下:
# 创建映射并定义字段内容分词的正则表达式
PUT myindex
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern",
"pattern": "[0-9]{3}"
}
}
}
}
}
# 对指定内容根据“my_analyzer”分词
POST myindex/_analyze
{
"analyzer": "my_analyzer",
"text": "id-123-4567-890-xxd9-689-x987"
}
分词后得结果如下图所示:
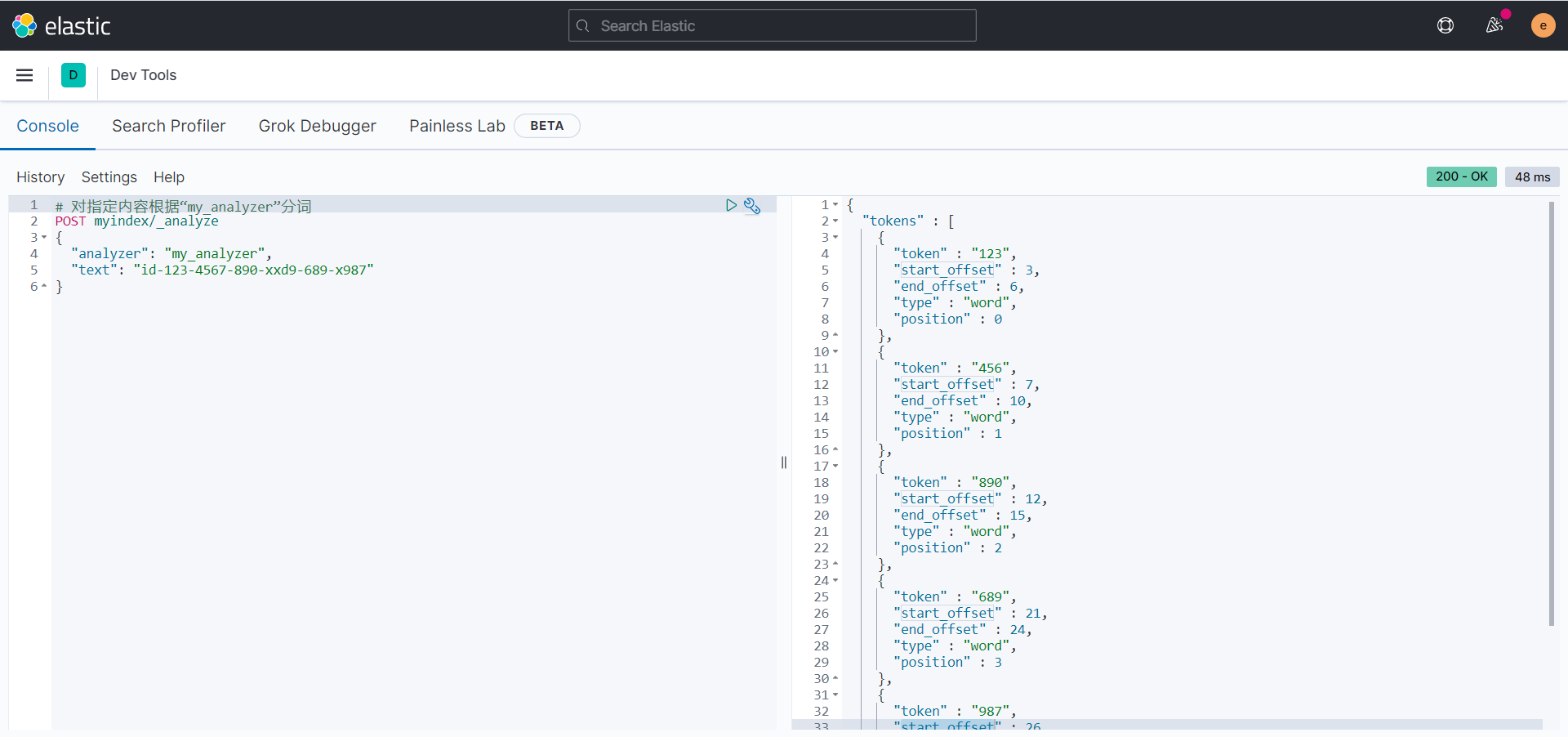
由以上分词信息可知,内容“id-123-4567-890-xxd9-689-x987”被分词为如下结果:
[123, 456, 890, 689, 987]
分词结果符合预期:如果连续有3个数字在一起,则被当作一个单词。
simple_pattern_split分词器
simple_pattern_split(指定分词符号)分词器比simple_pattern分词更有限,但是分词效率较高。默认模式下,它的分词匹配符号是空字符串。需要注意的是,使用此分词器应该根据业务进行配置,而不是简单地使用默认匹配模式。范例如下:
# 创建索引映射并指定内容分词匹配符号
PUT myindex
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "simple_pattern_split",
"pattern": "-"
}
}
}
}
}
# 对指定内容根据“-”分隔符匹配规则进行分词
POST myindex/_analyze
{
"analyzer": "my_analyzer",
"text": "ZF3R0-FHED2-M80TY-8QYGC-NPKYF"
}
分词后的结果如下:
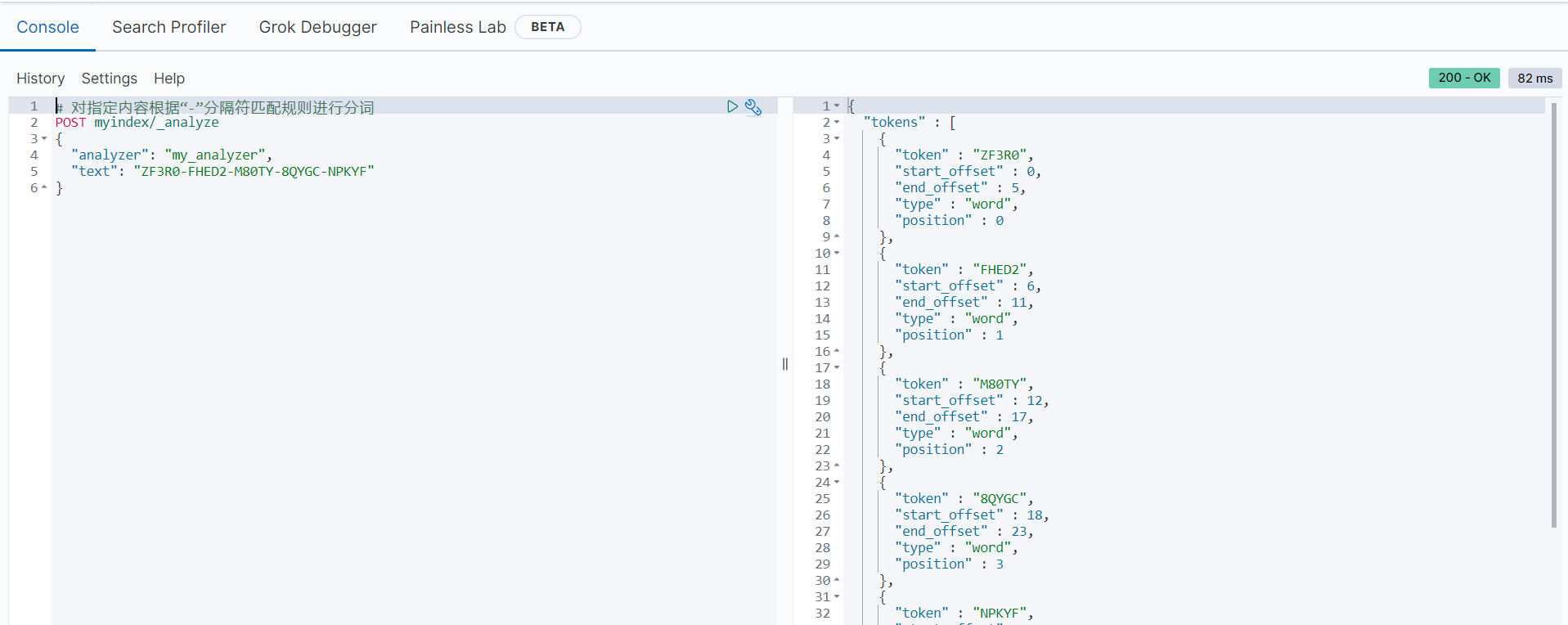
由以上分词信息可知,内容“ZF3R0-FHED2-M80TY-8QYGC-NPKYF”根据“-”分隔符分词后的结果是:[ZF3R0, FHED2, M80TY, 8QYGC, NPKYF]。结果符合预期。
standard分词器
standard(标准)分词器是Elasticsearch中默认的分词器,它是基于Unicode文本分割算法进行分词的。范例如下:
# 对指定内容根据standard分词器进行分词
POST _analyze
{
"analyzer": "standard",
"text": "China Eastern Airlines flight MU5735: debris and belongings recovered but search for survivors continues"
}
分词后的结果如下:
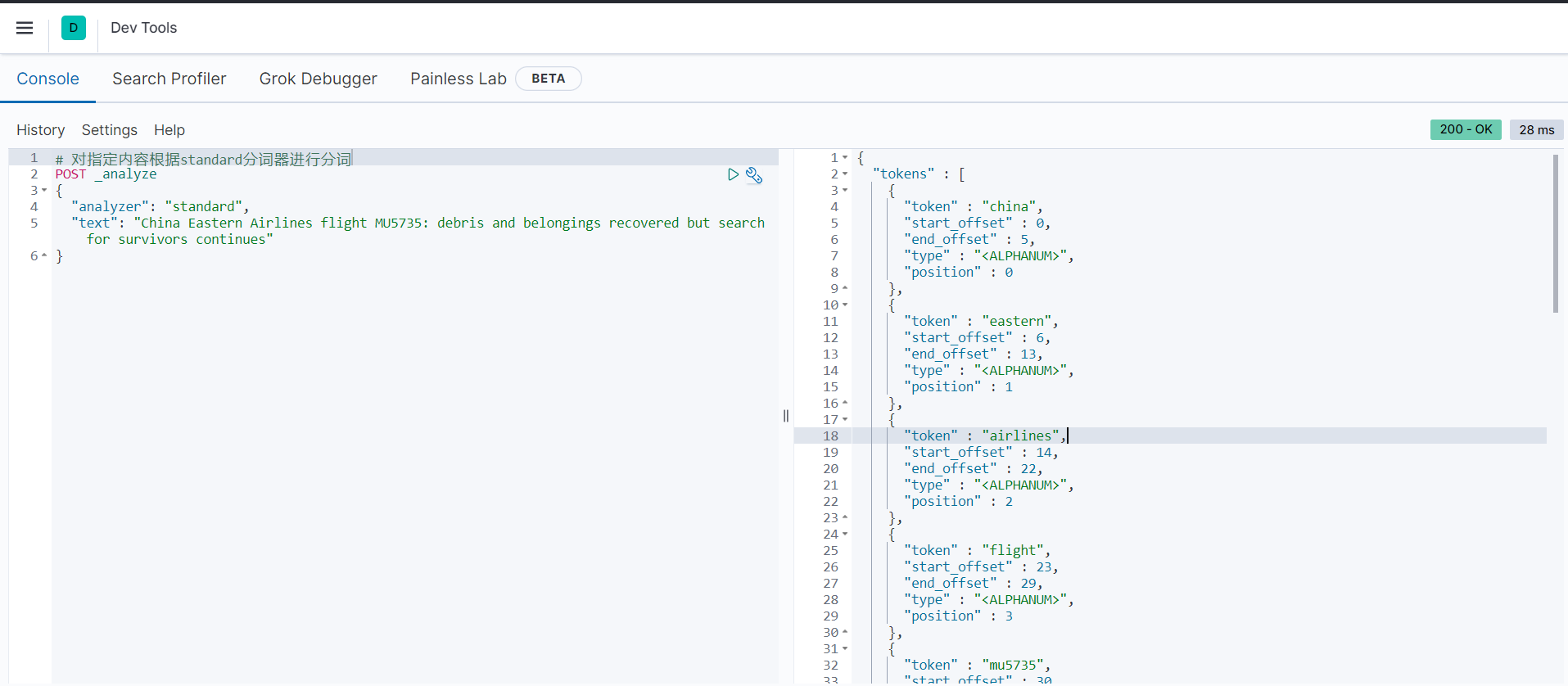
从分词结果可以看出,内容“China Eastern Airlines flight MU5735: debris and belongings recovered but search for survivors continues”被分成了14个关键字:
["china", "eastern", "airlines", "flight", "MU5735", "debris", "and", "belongings", "recovered", "but", "search", "for", "survivors", "continues"]
standard分词器还提供了以下两种参数:
范例如下:
# 创建索引映射,对分词规则进行配置,规则是分词后单词的最大长度为6,根据英语语法进行分析
PUT myindex
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"type": "standard",
"max_token_length": 6,
"stopwords": "**english**"
}
}
}
}
}
# 对指定内容根据如上规则进行分词
POST myindex/_analyze
{
"analyzer": "english_analyzer",
"text": "No survivors found as search continues in China Eastern flight MU5735 plane crash"
}
分词后的结果如下:
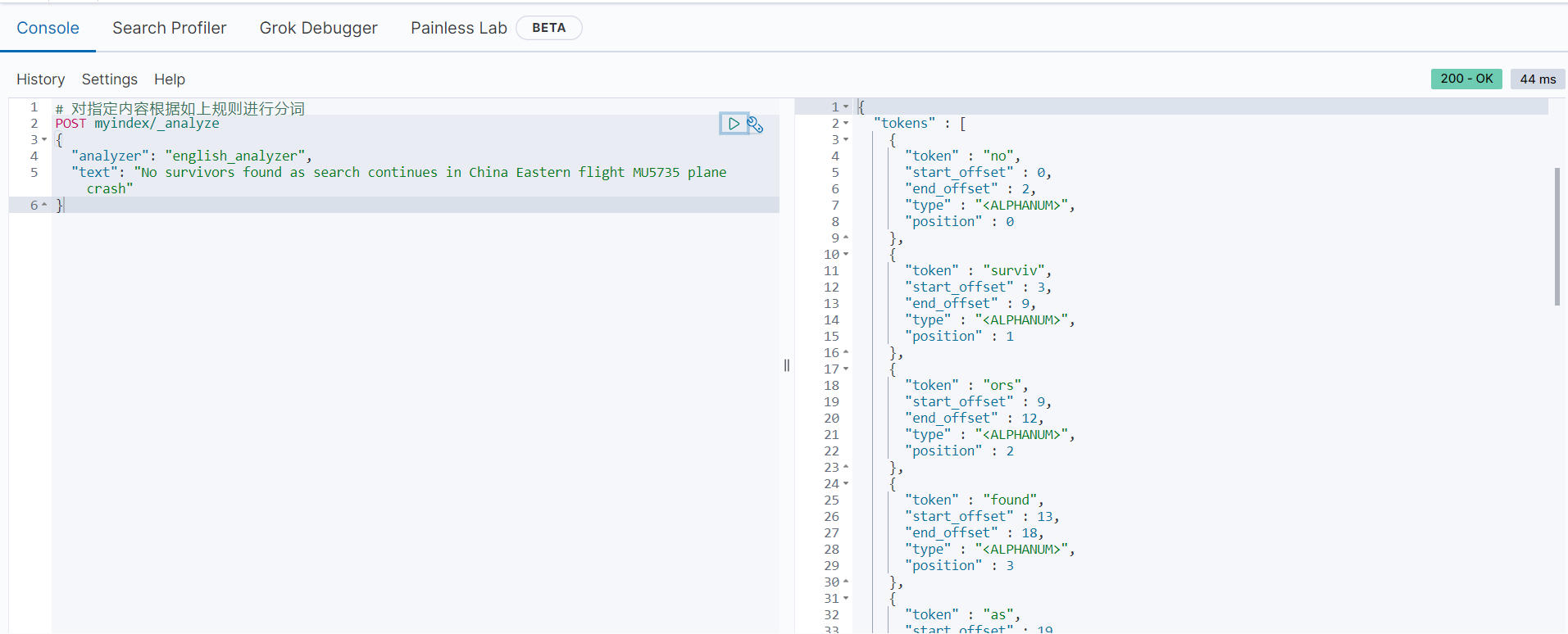
从分词可以看出,内容“No survivors found as search continues in China Eastern flight MU5735 plane crash”被分成了16个关键字:
["no", "surviv", "ors", "found", "as", "search", "contin", "ues", "in", "china", "easter", "n", "flight", "mu5735", "plane", "crash"]
需要注意的是,“continues”和“Eastern”本身是一个完整的单词,但是因为我们配置了max_token_length等于6,也就是分词后单词的最大长度是6,从而这两个单词被分别拆分成了“contin”、“ues”和“easter”、“n”。因此在实际应用中,要慎重配置这些参数,因为它们会影响全文搜索的结果。
自定义与standard类似的分词器
如果希望自定义一个与standard类似的分词器,用户只需要在原定义中配置参数即可。范例如下:
# 创建索引映射,自定义一个分词器规则:根据关键字类型分词,将单词全部转成小写
PUT myindex
{
"settings": {
"analysis": {
"analyzer": {
"rebuild_analyzer": {
"type": "keyword",
"tokenizer": "standard",
"filter": ["lowercase"]
}
}
}
}
}
# 对指定内容根据如上自定义的分词规则进行分词
POST myindex/_analyze
{
"text": "The flight was carrying 132 people, including 123 passengers and nine crew members"
}
分词后的结果如下:
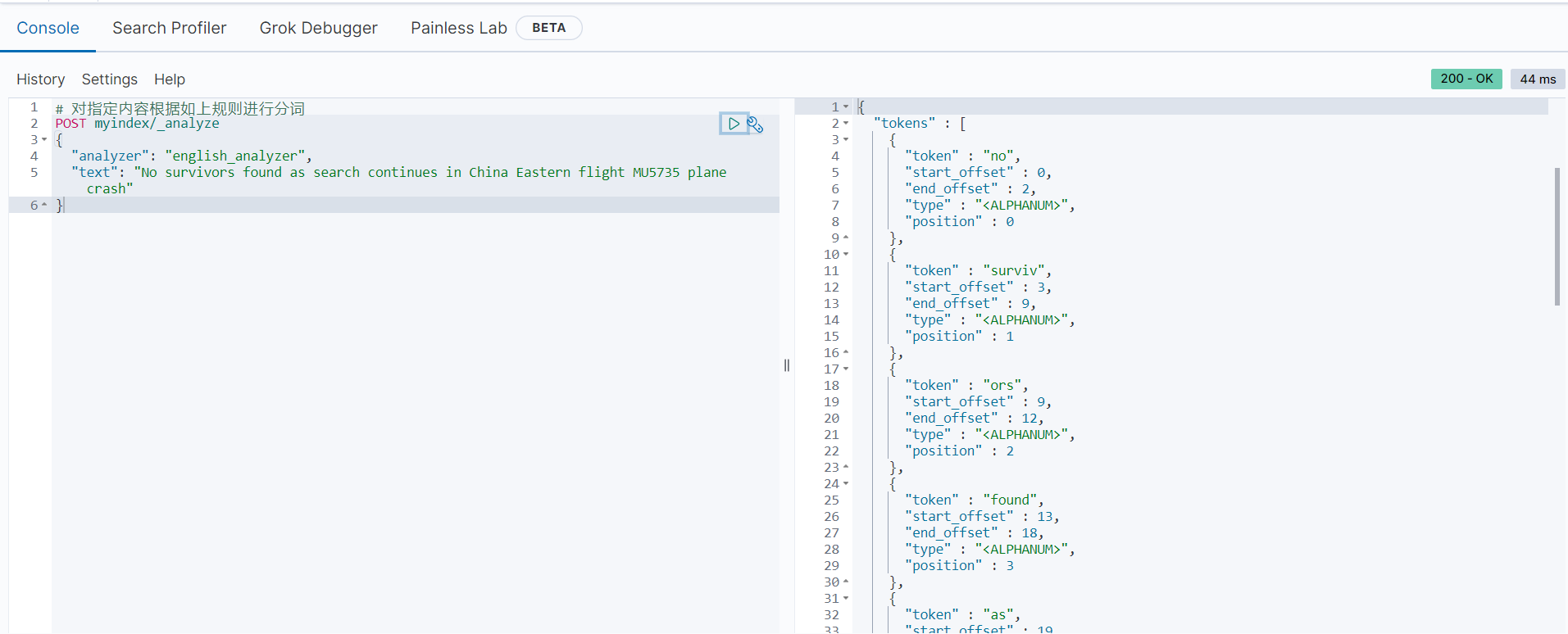
从分词结果可以看出,内容“The flight was carrying 132 people, including 123 passengers and nine crew members”被分成了13个关键字,并将单词都转换为小写。


