Redis哨兵细节分析

sdown与odown
Redis Sentinel有两个不同概念的下线:一个被称为主观下线sdown,一个被称为客观下线odown。
哨兵集群的自动发现机制
Sentinel和其他的Sentinel保持连接是为了互相之间检查是否可达和交换消息。然而,我们不需要在每个运行的Sentinel实例中配置其他的Sentinel地址列表,Sentinel使用Redis实例的发布与订阅功能来发现部署中用于监控相同主节点和从节点的其他Sentinel:
故障转移的重新配置
即使没有故障转移,Sentinel也将尝试把当前的配置设置到监控的实例上。特别注意如下两点:
Sentinel重新配置从节点,错误的配置在一段时间内会被观察到,这比广播新的配置方式更好,这样可以阻止过时的配置,比如在一个分区中重新加入的Sentinel在收到更新之前会去交换从节点的配置。需要注意如下事项:
从节点选举和优先级
当一个Sentinel实例准备执行故障转移时,主节点这时在odown状态下,Sentinel会收到从大多数已知的其他Sentinel实例中授权开始故障转移的消息,于是一个合适的从节点会被选举出来。
从节点选举过程评估下列信息:
一个从节点被发现从主节点断开超过主节点配置时间down-after-milliseconds选项10倍以上,加上从正在执行故障转移的Sentinel的角度来看主节点不可用的时间,该从节点将被认为是不合适被选举的。在更为严格的条件下,一个从节点从主节点断开超过以下时长将被认为是不可靠的:
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state选举只会考虑通过了上述测试的从节点,并根据上面的条件进行排序,排序说明如下:
如果按优先级选,那么Redis主节点、从节点都必须配置相应的slave-priority;否则所有的实例都要有一个默认的ID。为了永远不被Sentinel选择为新的主节点,Redis实例可以把slave-priority配置为0,一个这样配置的从节点会被Sentinel重新配置,唯一不同的是它永远不会成为主节点。
算法和内部结构
每个被Sentinel监控的主节点与一个配置的quorum相关联,它指定了同意主节点是不可达的或者是错误的所需的Sentinel实例的数量。
在故障转移触发后,为了真正地执行故障转移,大多数的Sentinel必须授权一个Sentinel开始执行故障转移。当只有小部分Sentinel在一个网络分区中,那么故障转移永远不会执行。
如果有5个Sentinel实例,quorum被设置为2,一旦两个Sentinel认为主节点不可达,故障转移就会被触发。然而这两个Sentinel中的一个得到了其他3个Sentinel的授权才会开始执行故障转移。把quorum设置为5,就必须所有这5个Sentinel实例同意主节点失败。为了开始故障转移,需要得到所有Sentinel实例的授权。
这意味着quorum在两方面可以用来调整Sentinel:
配置epoch
为了启动故障转移,需要从大多数Sentinel中得到授权,重要原因如下:
配置广播
一旦一个Sentinel能成功地对一个主节点执行故障转移,它就将开始广播新的配置,以便其他Sentinel更新它们关于主节点的信息。
为了认定一次故障转移是成功的,需要Sentinel能发送SLAVEOF NO ONE命令给被选举出来的从节点,然后切换为主节点,稍后就能在主节点的INFO输出中观察到。
这时,从节点的重新配置正在进行,故障转移也被认为是成功的,并且所有的Sentinel需要开始报告新的配置。
为新配置采用广播方式的原因是,在每次Sentinel被授权故障转移时有一个不同的版本号。每个Sentinel使用Redis发布与订阅消息来连续不断地广播它的主节点配置的版本号、所有的从节点和主节点。同时,所有的Sentinel等待消息来查看其他的Sentinel广播的配置。
配置在__sentinel__:hello发布与订阅频道中被广播。因为每个配置都有一个不同的版本号,大的版本号总是赢得小的版本号。比如一开始所有的Sentinel认为主节点mymaster的配置为192.168.118.128:6379,这个配置的版本号为1。一段时间后,被授权启动故障转移有了版本号2,如果故障转移成功,它将广播新的配置(192.168.118.128:6380,版本号为2)。所有其他的实例将看到这个配置并更新它们的配置,因为新的配置有更高的版本号。
这意味着Sentinel保证第二个活性属性:一个Sentinel集合能互相交流并且把配置信息收敛到一个更高的版本号。
基本上,如果网络是分区的,那么每个分区将收敛到一个更高的本地配置。在没有网络分区的特殊情况下,只有一个分区,那么每个Sentinel将同意这个本地配置。
网络分区下的一致性
Redis Sentinel配置最终是一致的,所以每个分区将收敛到更高的可用配置。在使用Sentinel的真实世界系统中,有三个不同的角色:
为了定义系统的行为,这三种角色我们都考虑。有一个简单的三个节点网络,每个节点中都运行一个Redis实例和一个Sentinel实例,整体架构图如图所示:
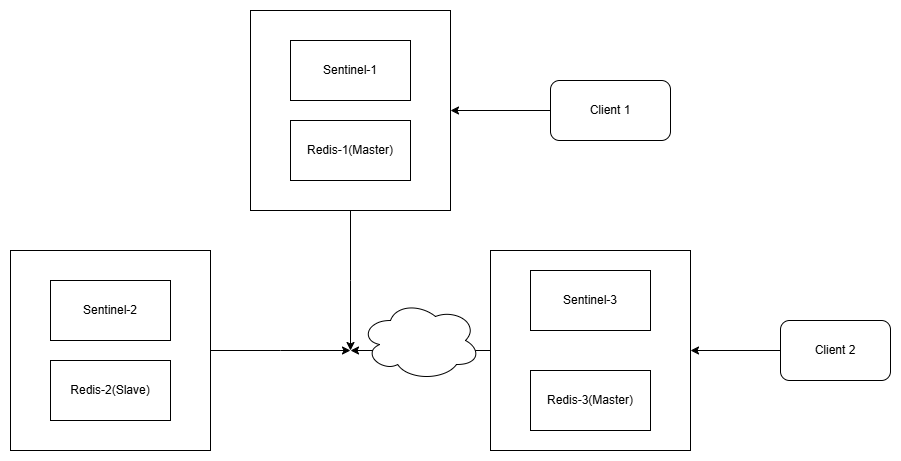
在这个系统中,原始状态是Redis-3是主节点,Redis-1和Redis-2是从节点。一个网络分区隔离了旧的主节点。Sentinel-1和Sentinel-2启动故障转移过程,把Sentinel-1提升为新的主节点。
Sentinel的属性保证Sentinel-1和Sentinel-2有了一个主节点的新配置。但Sentinel-3依然是旧的配置,因为它在一个不同的网络分区中存活。
Sentinel-3将会更新它的配置,当网络分区治愈时,如果有客户端和旧的主节点在一起,客户端仍然可以向Redis-3写入数据。当网络分区治愈时,Redis-3变成Redis-1的一个从节点,在网络分区治愈期间写入的数据都会丢失。可以通过修改配置选择是否让这种情况发生:
Redis是采用异步复制的,这种情况下没有办法完全阻止数据的丢失,但是可以使用下面的Redis配置选项来限制Redis-3和Redis-1之间的不一致性:
min-slaves-to-write 1
min-slaves-max-lag 10上面这两个配置可以减少异步复制和脑裂split-brain导致的数据丢失,要求至少有1个从节点,数据复制和同步的延迟不能超过10秒。一旦所有从节点的数据复制和同步的延迟都超过了10秒,那么主节点就不会再接收任何命令请求了。
减少异步复制的数据丢失
有了min-slaves-max-lag这个配置选项,就可确保一旦从节点复制数据和确认ack延时太长,进而认为主节点宕机后损失的数据太多了,拒绝写请求,这样可以把主节点宕机时由于部分数据未同步到从节点而导致的数据丢失降低到可控的范围内。
减少脑裂的数据丢失
假如一个主节点出现了脑裂,与其他从节点的连接丢失了,上面的两个配置含义是如果不能继续给指定数量的从节点发送数据,而且从节点超过10秒没有给主节点发送确认消息,就直接拒绝客户端的写请求。这样脑裂后旧的主节点就不会接收客户端的新数据,也就避免了数据的丢失。因此,在脑裂场景下,最多丢失10秒的数据。
总之,Redis+Sentinel是一个最终一致性系统eventually consistent system,即最后一次的故障转移成功last failover wins。旧节点中的数据会被丢弃,从当前主节点复制数据,所以总有一个丢失确认写的窗口。这是由Redis的异步复制和系统的“虚拟”合并功能的丢弃性质决定的。

Golang控制协程(goroutine)的并发数量
4/17/2025减小Go代码编译后的二进制体积
4/17/2025
Rust Match全模式列表
1/9/2025
Redis哨兵细节分析
12/12/2024