Elasticsearch组合查询(一)

组合查询的布尔查询
布尔查询是组合查询中常用的查询方式,它将多个查询条件组合在一起,并且将查询的结果和结果的评分组合在一起。当查询条件是多个表达式的组合时,布尔查询将变得非常有用。实际上,布尔查询是把多个子查询组合成一个布尔表达式,所有子查询之间的逻辑关系是and,只有当一个文档满足布尔查询中的所有子查询条件时,Elasticsearch引擎才认为该文档满足查询条件。布尔查询有以下两个特点:
范例一: 搜索同时满足must、must_not和should子句条件的数据
POST myindex/_bulk
{"index":{}}
{"name": "张三", "address": "china shanghai", "age": 18, "score": 60, "tags": "emp manager love"}
{"index":{}}
{"name": "张三", "address": "china hangzhou", "age": 18, "score": 70, "tags": "emp love"}
{"index":{}}
{"name": "王五", "address": "china shanghai", "age": 20, "score": 60, "tags": "emp manager"}
{"index":{}}
{"name": "张三", "address": "china shanghai", "age": 21, "score": 60, "tags": "emp love"}
# 查询address字段中包含china单词,tags字段中emp单词,age不在20和30之间,且满足tags字段包含manager或love中的一项的字段
GET myindex/_search
{
"query": {
"bool": {
"must": {
"term": {
"address": "china"
}
},
"filter": {
"match": {
"tags": "emp"
}
},
"must_not": [
{"range": {
"age": {"gte": 20, "lte": 30}
}}
],
"should": [
{"term": {"tags": "manager"}},
{"term": {"tags": "love"}}
],
"minimum_should_match": 1
}
}
}返回结果如下:
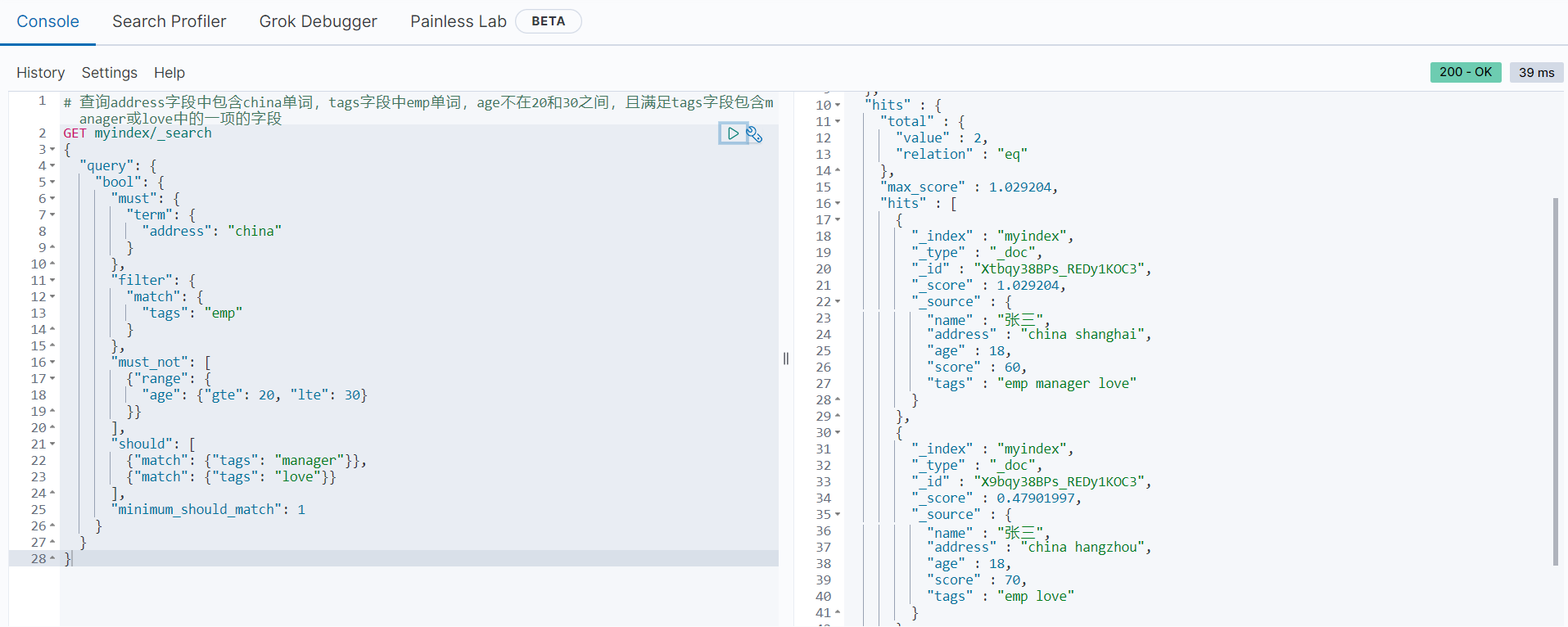
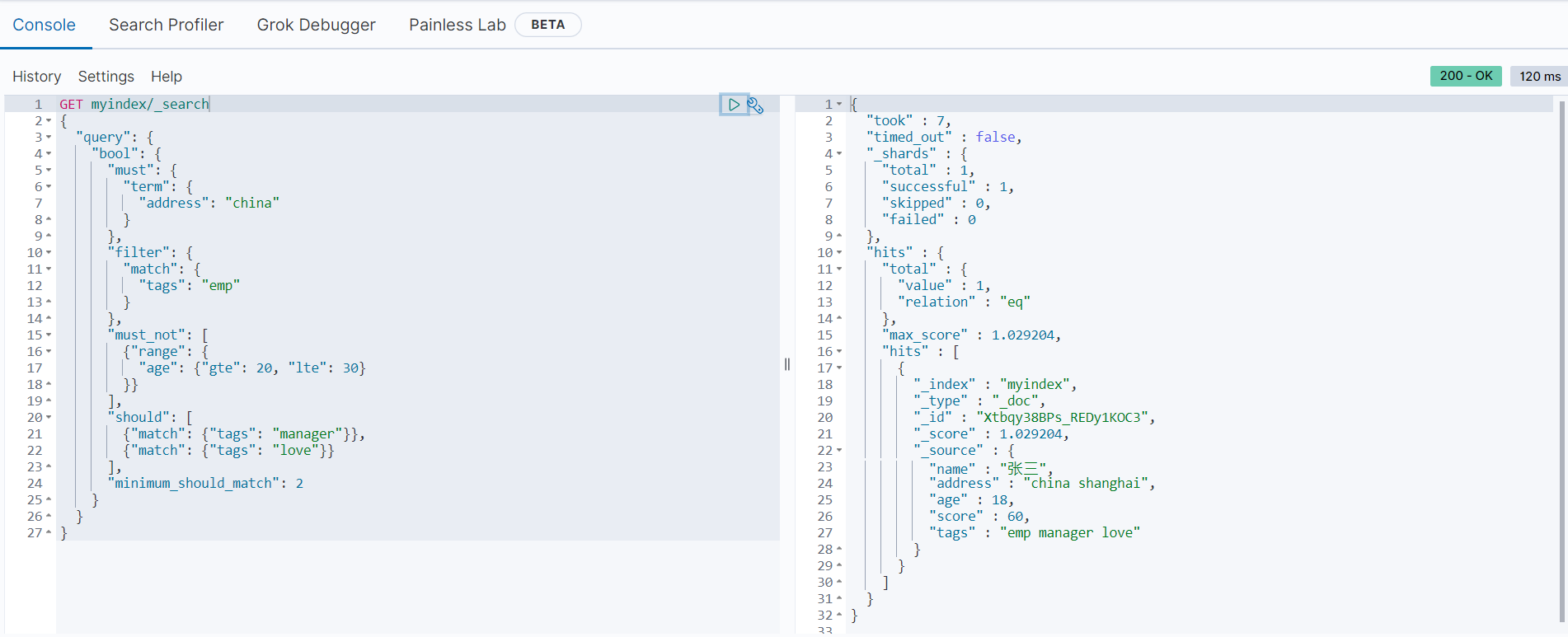
以上结果符合我们的查询要求。minumum_should_match选项需要特别注意,**表示should选项条件中最少命中的分词数量。**我们把上面语句的minimum_should_match选项设置为2,返回结果如下:
组合查询的提高评分查询
提高评分boosting查询不同于布尔查询,在布尔查询中只要一个子查询的条件不匹配,那么此文档数据就不符合要求。提高评分查询其实是降低文档评分,比如查询条件是"name" = "张三" and "address" = "china",对于只满足部分条件的文档数据,不是不返回,而是降低显示的优先级(也就是评分字段的值)。范例如下:
POST /myindex-boosting/_bulk
{ "index": {"_id": 1} }
{ "name": "张三", "address": "china shanghai" }
{ "index": {"_id": 2} }
{ "name": "王五", "address": "china beijing " }
{ "index": {"_id": 3} }
{ "name": "李四", "address": "china shenzhen" }
# 查询address字段中是否包含,并对包含beijing的字段做降级处理(降低评分)
GET /myindex-boosting/_search
{
"query": {
"boosting": {
"positive": {
"term": {
"address": "china"
}
},
"negative": {
"term": {
"address": "beijing"
}
},
"negative_boost": 0.5
}
}
}negative_boost(Required, float) 浮点值,小于1表示降低评分,大于1表示提高评分。执行结果如图所示:
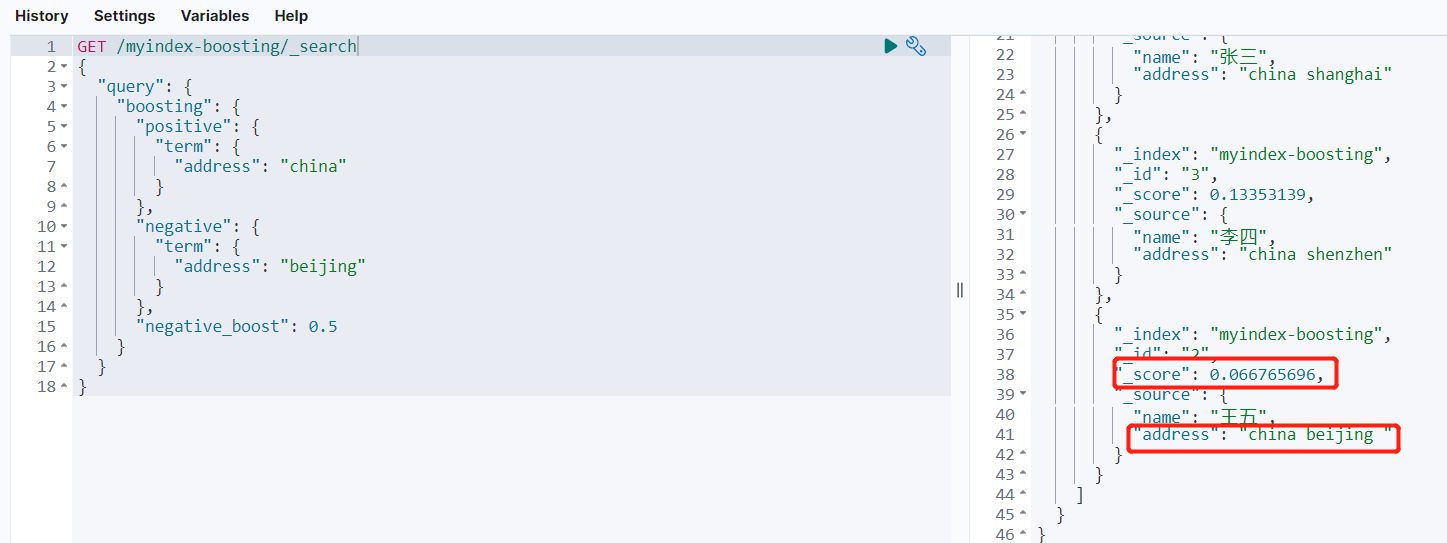
可以看到,包含beijing内容的文档评分明显较低。同理,也可以修改negative_boost字段的值,对匹配的文档提高评分。范例如下:
GET /myindex-boosting/_search
{
"query": {
"boosting": {
"positive": {
"term": {
"address": "china"
}
},
"negative": {
"term": {
"address": "beijing"
}
},
"negative_boost": 1.5 # 提高评分
}
}
}执行结果如下:
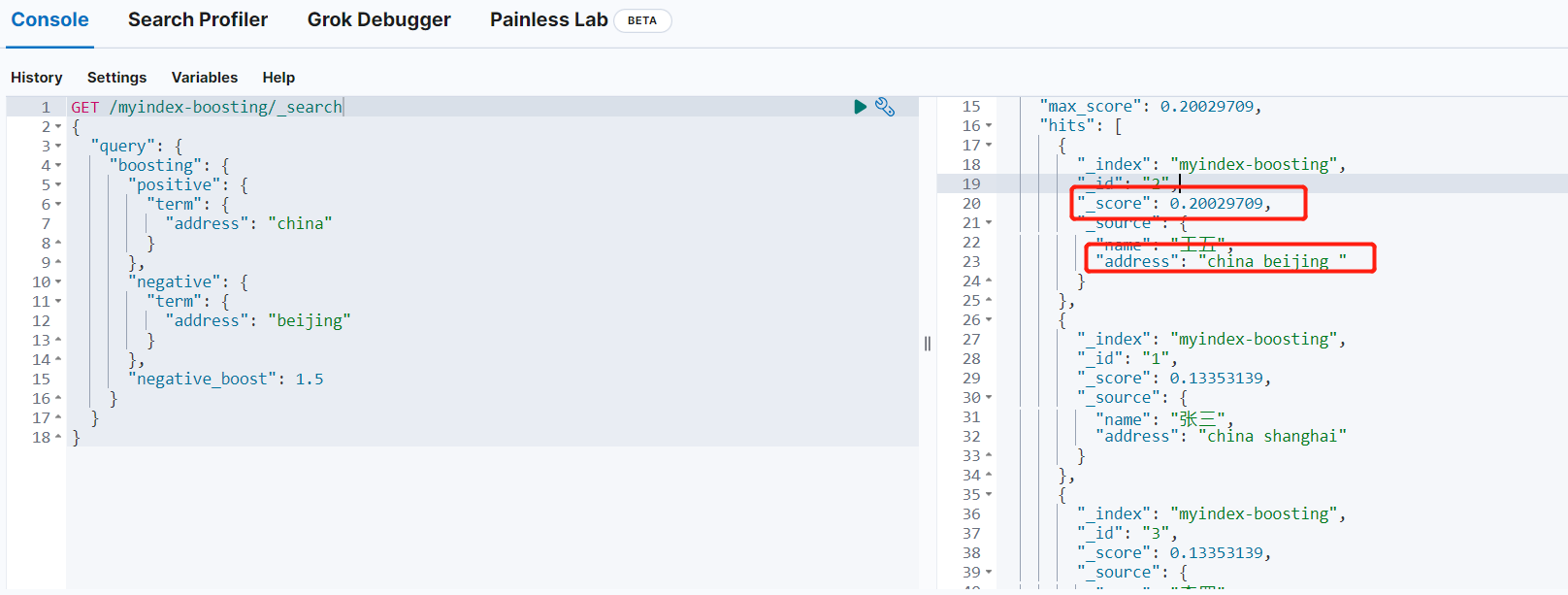
可以看到,包含beijing内容的文档分数明显提高,返回结果符合预期。
组合查询的固定评分查询
当根据某个条件查询时,如果需要返回固定评分constant_score,只需要使用filter和constant_score进行处理。范例如下:
POST /myindex-constant/_bulk
{ "index": {"_id" : 1} }
{ "content": "china shanghai" }
{ "index": {"_id" : 2} }
{ "content": "china beijing" }
{ "index": {"_id" : 3} }
{ "content": "america new york" }
# 固定评分查询
GET /myindex-constant/_search
{
"query": {
"constant_score": {
"filter": {
"term": {"content": "china"}
},
"boost": 1.2
}
}
}返回结果如下:
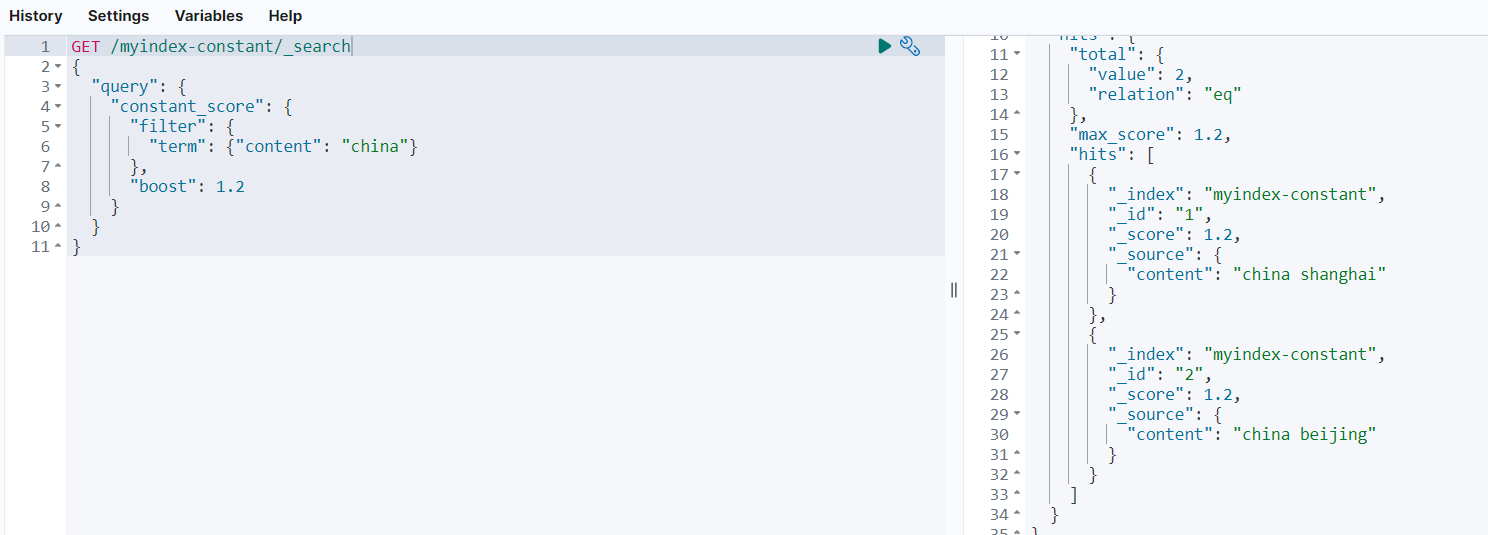
可以看到,查询返回的结果分数都是1.2,符合预期。
组合查询的最佳匹配查询
dis_max指的是在文档匹配中,只将最佳匹配的评分作为查询的评分结果返回。范例如下:
POST myindex-dis-max/_bulk
{ "index": {"_id": 1} }
{ "title": "Manchester City 4-1 Liverpool", "body": "Manchester City maintained the pressure on Premier League leaders Arsenal by shrugging off the absence of the injured Erling Haaland to outclass Liverpool with a magnificent display at Etihad Stadium." }
{ "index": {"_id": 2} }
{ "title": "A huge moment for Arsenal and for Jesus", "body": "Leeds fans could have been forgiven for fearing the worst after watching Gabriel Jesus open the scoring for Arsenal on Saturday." }如果用户要在title和body字段中查询包含leaders Arsenal的文档,那么很有可能只是想搜索与leaders Arsenal相关的词。根据上面两条文档我们可以判断出_id为1的文档匹配度更高一些,因为leaders Arsenal在此文档中的内容是连续的。
先通过厦门语句查询:
GET /myindex-dis-max/_search
{
"query": {
"bool": {
"should": [
{"match": {"title": "leaders Arsenal"}},
{"match": {"body": "leaders Arsenal"}}
]
}
}
}返回结果如下:
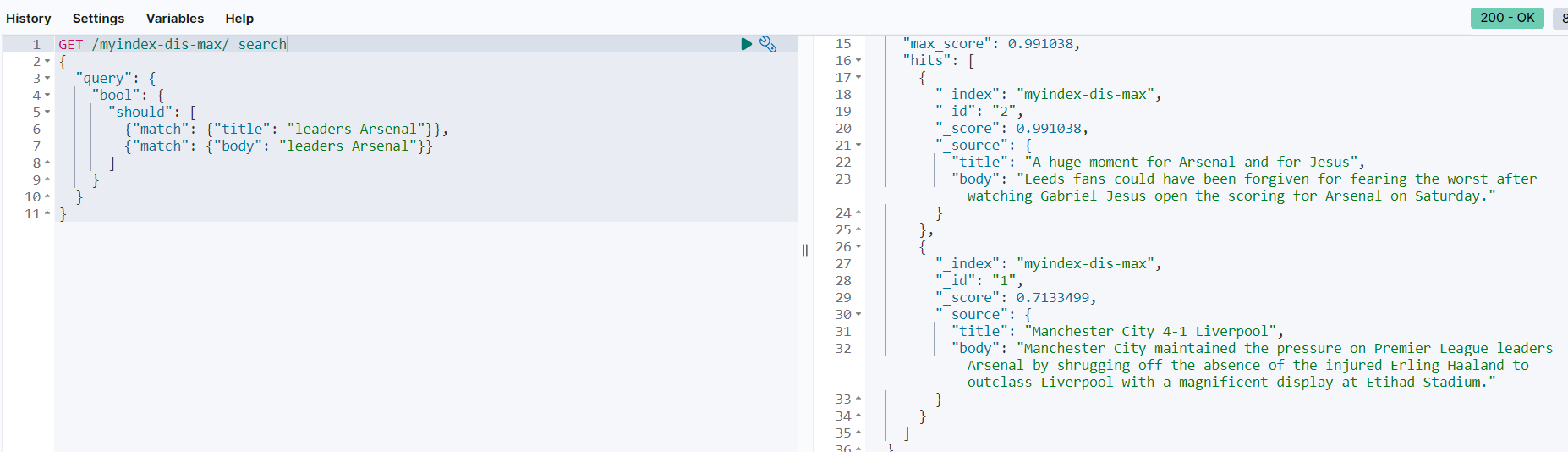
从上面结果可以看出,_id等于2的文档评分是0.991038,_id等于1的文档评分是0.7133499。这与预期结果不一致。面对这种情况,这时可以使用dis_max进行查询。范例如下:
GET /myindex-dis-max/_search
{
"query": {
"dis_max": {
"tie_breaker": 0,
"queries": [
{"match": {"title": "leaders Arsenal"}},
{"match": {"body": "leaders Arsenal"}}
]
}
}
}返回结果如下:
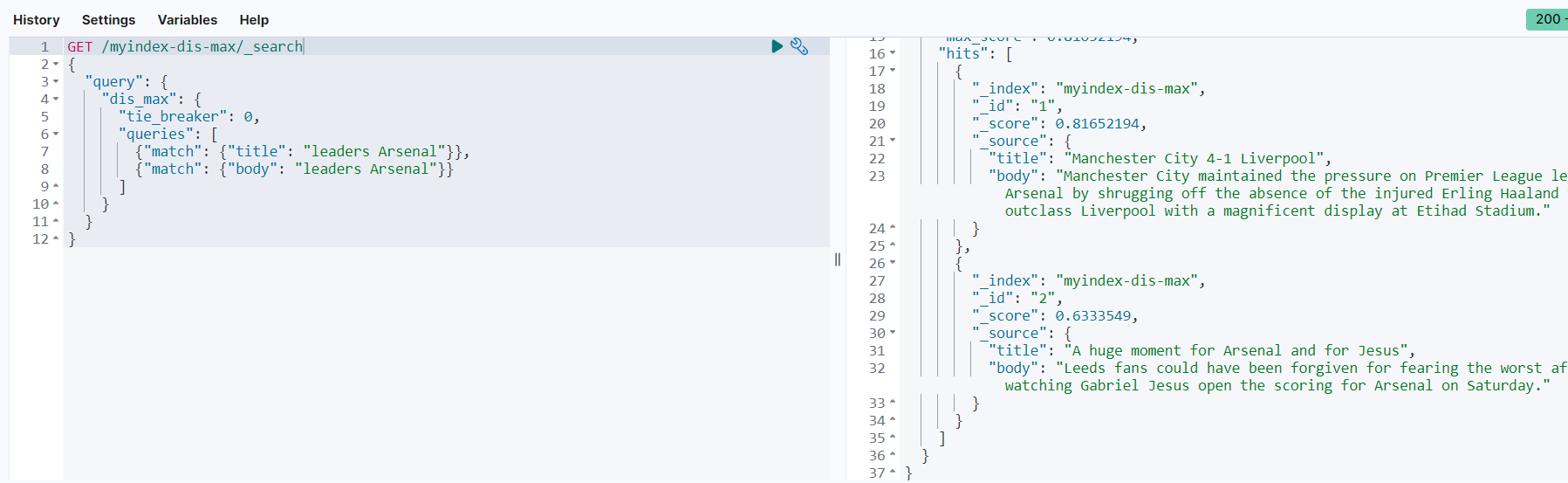
可以看到_id等于1的文档评分是0.81652194,_i等于2的文档评分是0.6333549。查询结果符合预期。
dis_max参数说明:queries(Required):数组查询对象,包含一个或多个查询子句。返回的文档必须匹配这些查询中的一个或多个。如果一个文档匹配多个查询,elasticsearch会使用最高的相关性分数。tie_breaker(Optional, float):可以是 0 到 1 之间的浮点数,其中 0 代表使用 dis_max 最佳匹配语句的普通逻辑, 1 表示所有匹配语句同等重要。最佳的精确值需要根据数据与查询调试得出,但是合理值应该与零接近(处于 0.1 - 0.4 之间),这样就不会颠覆 dis_max 最佳匹配性质的根本。
Golang控制协程(goroutine)的并发数量
4/17/2025减小Go代码编译后的二进制体积
4/17/2025
Rust Match全模式列表
1/9/2025
Redis哨兵细节分析
12/12/2024