

©2024 Powered By TrumanWong
缓存穿透、缓存击穿和缓存雪崩详解
缓存穿透
首先我们来了解下面这个基本操作:
graph LR
A[客户端] --> B(业务服务)
B --> C(MySQL服务)
当客户端发送数据请求的时候,服务业务会执行MySQL数据库或者将结果返回给客户端,当然这在并发量少的时候没有任何问题。如果并发量比较大,每一次请求数据都要操作MySQL数据库,那么就需要执行阻塞的IO操作。最简单、最廉价的方法就是缓存,此时操作流程就会演变成如下图所示的业务架构图:
graph TD
A[客户端] --> B[业务服务]
B --> C{数据是否在缓存中}
C --> |是| B
C --> |不存在| D(查询数据库)
D --> |更新缓存数据|C
需要注意的是:当查询Redis中没有数据时,该查询会下沉到数据库层,同时数据库层也没有该数据,当出现大量这种查询(或被恶意攻击)时,接口的访问全部透过Redis访问数据库,而数据库中也没有这些数据,我们称这种现象为“缓存穿透”。缓存穿透会穿透Redis的保护,让底层数据库的负载压力变大。
如果大量请求查询的数据既不在缓存中,也不在MySQL数据库中,那么会造成每次的查询操作都会对数据库进行查询,因为不存在的数据是没有办法缓存的,于是就造成MySQL数据库承受高并发的查询请求,如下图所示:
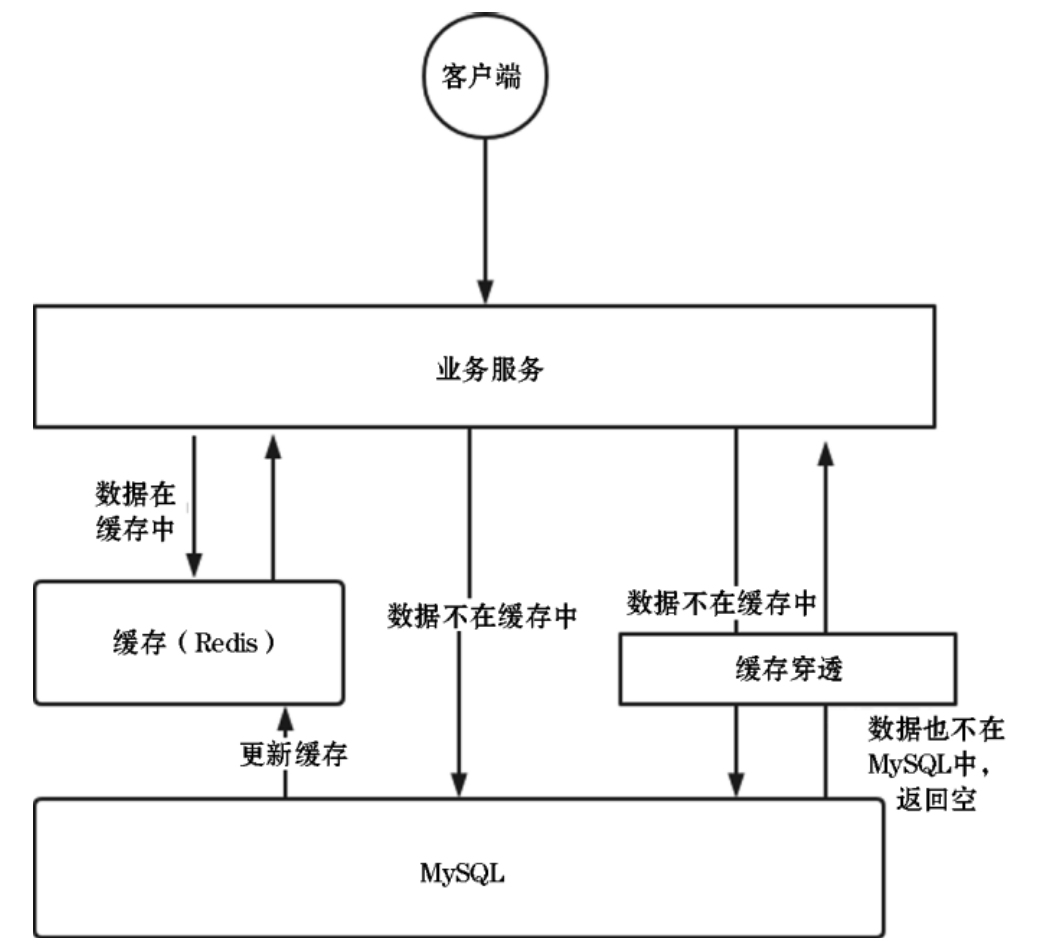
针对上面的问题,这里列出两个解决方案:
- 在业务服务访问层对用户进行校验来判断是不是来自恶意用户的请求,比如对请求参数进行校验和检查一段时间内请求同一个服务的次数。
- 利用布隆过滤器将数据库层有关数据的键存储到布隆过滤器中,以判断访问的键是否在底层的数据库中。如果在布隆过滤器中则查询缓存,如果缓存没有则再次查询
MySQL数据库;如果布隆过滤器中没有,则直接返回我们预先规定好的结果即可。
在数据访问的第一层我们采用布隆过滤器过滤,如下图所示,虽然不能完全避免数据穿透的现象,但布隆过滤器已经可以将99.99%的穿透查询屏蔽在Redis曾,极大地降低了底层数据库的压力,减少了资源浪费。
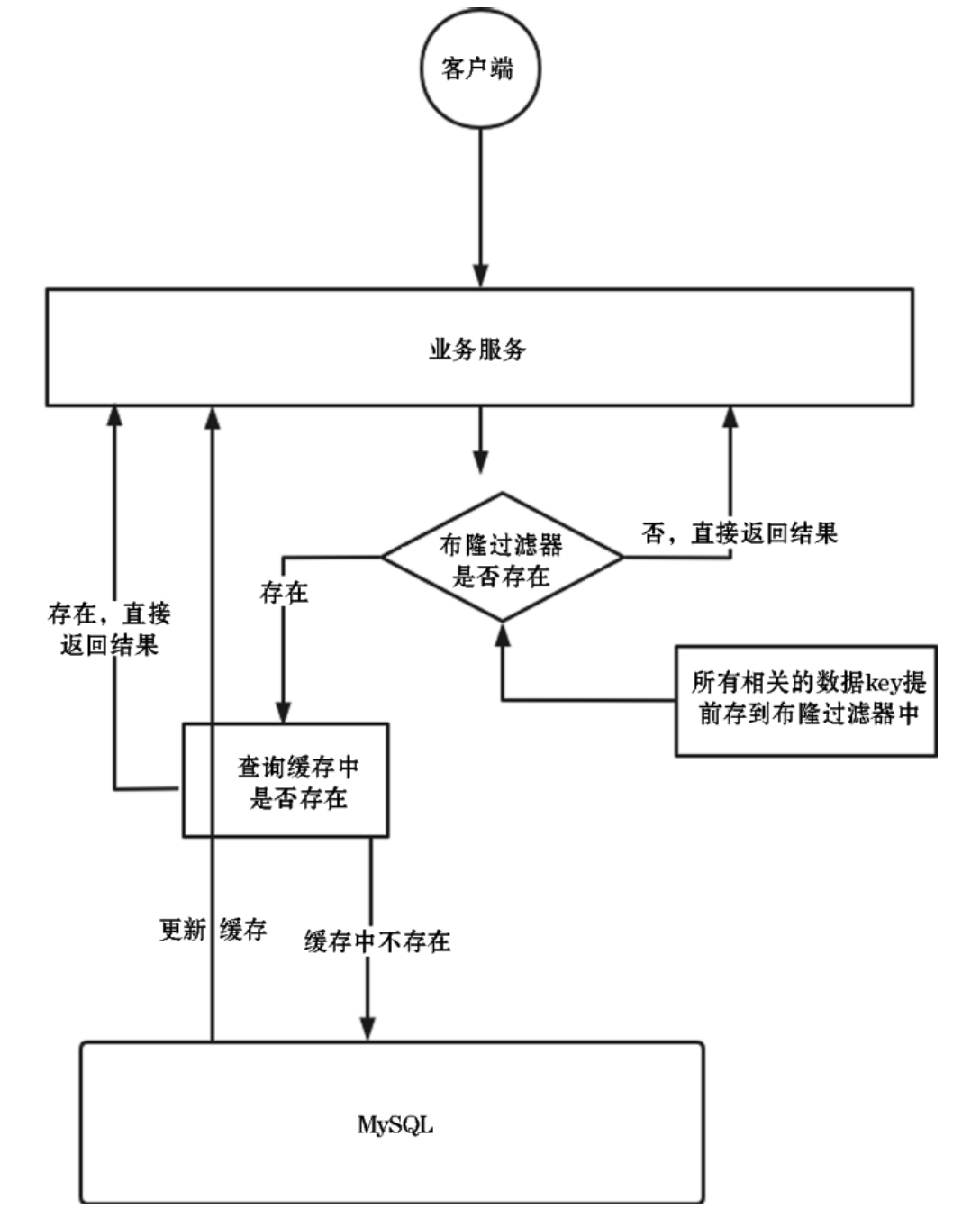
我们可以把布隆过滤器的层级放到缓存下一层,当请求数据的时候先去缓存层获取。如果缓存里面有数据,就直接返回结果;如果缓存没有,就去布隆过滤器判断相关数据的键是否在布隆过滤器中,如果在就继续查询MySQL数据库,如果不存在就直接返回,不再进行数据库层级的查询。
缓存击穿
缓存击穿和缓存穿透从名词上很难区分开,它们的区别主要是**“穿透”表示底层数据库没有数据而且缓存层也没有数据,而“击穿”表示底层数据库有数据但是缓存层没有数据**。当热点数据的键从缓存中淘汰出去后,大量访问同时请求这个数据就会将查询下沉到数据库层,此时数据库层的负载压力增大,我们称这种现象为缓存击穿。
graph TD
A(客户端1) --> B[Redis]
C(客户端2) --> B
D(客户端3) --> B
B --> E
B --> |当前缓存数据过期|E[MySQL]
B --> E
针对上面的问题,这里列出两种解决方案:
- 热点键的过期时间设置为永不过期。
- 利用互斥锁保证同一时刻只有一个客户端可以查询底层数据库的数据,一旦查到数据就缓存至
Redis内,以避免其他大量请求同时穿过Redis去访问底层数据库。
缓存雪崩
缓存击穿说的是热点数据过期,缓存雪崩说的是大面积的数据过期。缓存雪崩是指Redis中大量的键几乎同时过期,然后大量并发的查询穿过Redis冲击到底层数据库上,此时数据库层的负载压力会增大。相比于缓存击穿,缓存雪崩更容易发生。如下图所示,大量缓存同一时间过期造成了缓存雪崩问题:
graph TD
A(客户端1) --> D[Redis]
B(客户端2) --> |请求的key在同一时间都失效了|D
C(客户端2) --> D
D --> E[MySQL]
D --> |去数据库查询数据|E
D --> E
针对上面的问题,这里列出两种解决方案:
- 在可接受的时间范围内随即设置键的过期时间,分散键的过期时间,以防止大量的键在同一时刻过期。比如之前大量的键的过期时间都是1个小时,现在就可以设置为不同的时间段,比如1小时1分钟、1小时2分钟等。可以根据业务情况选择不同的随机因子。
- 键的过期时间设置为永不过期,根据实际业务情况而定。

Nginx利用访问日志、错误日志和请求跟踪进行调试和故障排除
- 6/21/2024
Nginx负载均衡配置
- 6/20/2024

Kafka管理命令(二):消费者群组
- 5/23/2024
Kafka管理命令(一):主题操作
- 5/22/2024