Elasticsearch分词器(二)

上文我们已经知道text字段类型会进行分词处理,然后根据分词后的单词建立倒排索引(反向索引),因而不支持聚合计算。keyword字段类型不会进行分词处理,直接根据字符串的内容建立倒排索引(反向索引),支持聚合计算和排序操作。下面将通过一个范例来认识keyword字段类型和text字段类型的区别。范例如下:
# 创建索引映射
PUT myindex
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
# 插入文档数据
POST myindex/_doc
{
"name": "曹操",
"address": "魏国",
"age": 18
}
# 插入文档数据
POST myindex/_doc
{
"name": "张辽",
"address": "魏国",
"age": 19
}
# 插入文档数据
POST myindex/_doc
{
"name": "刘备",
"address": "蜀国",
"age": 30
}
# 插入文档数据
POST myindex/_doc
{
"name": "姜维",
"address": ["魏国", "蜀国"],
"age": 20
}
POST myindex/_doc
{
"name": "孙十万",
"address": "吴国",
"age": 35
}下面进行搜索操作:
# 对name字段进行全文搜索,搜索包含”曹操“的文档数据
GET myindex/_search
{
"query": {
"match": {
"name": "曹操"
}
}
}
# 对address字段进行全文搜索,搜索包含”魏国“的文档数据
GET myindex/_search
{
"query": {
"match": {
"address": "魏国"
}
}
}搜索结果如下:
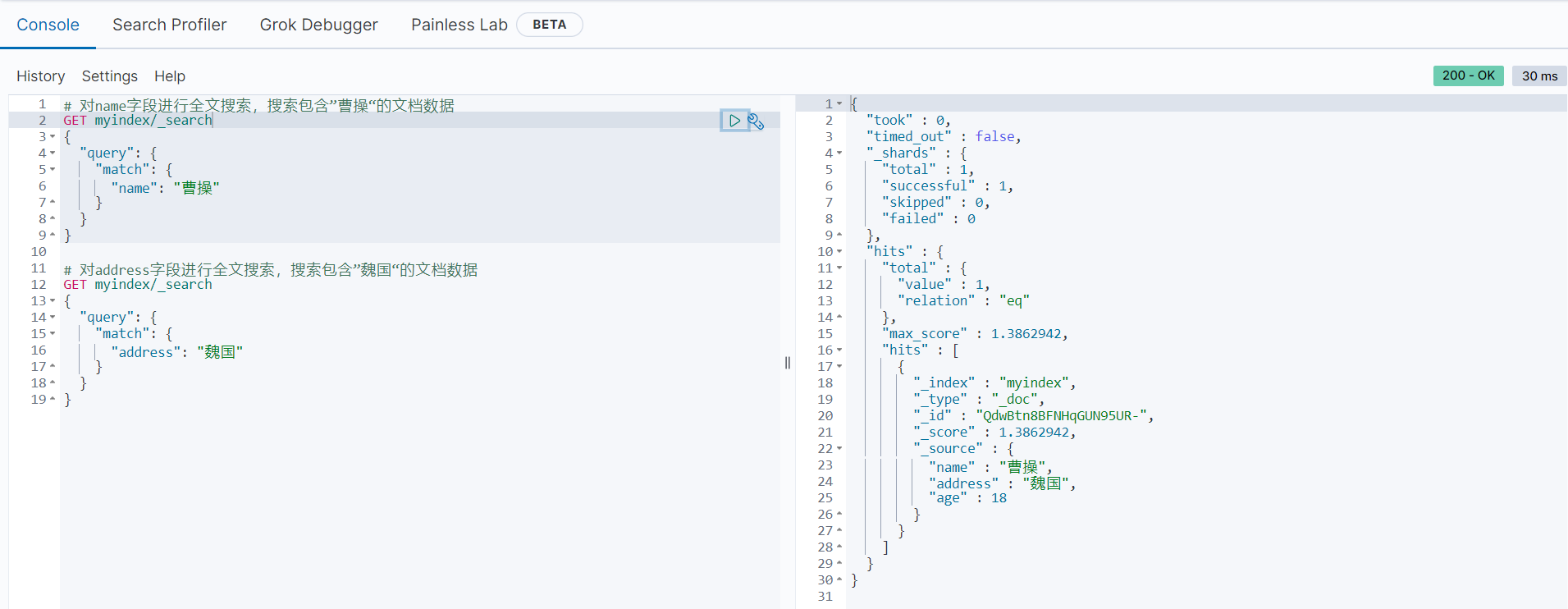
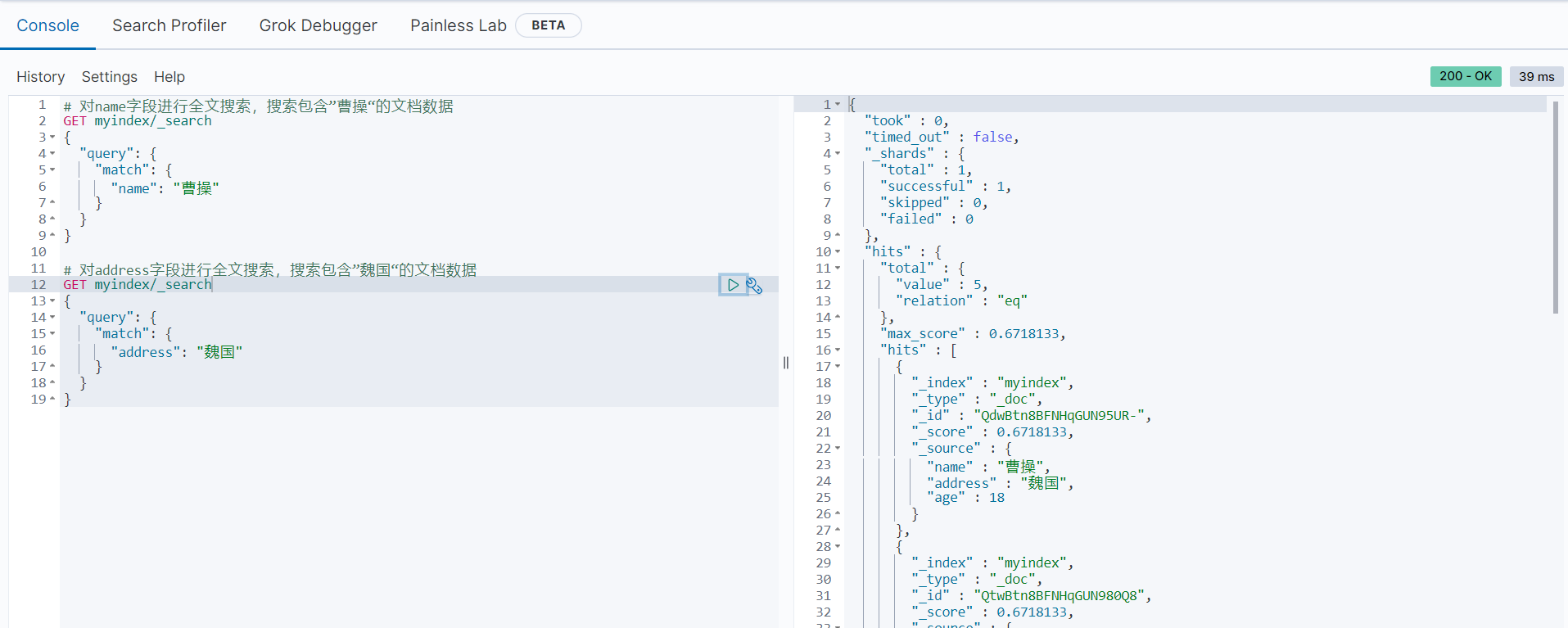
从搜索结果可以看出,第一个搜索操作,我们只搜索到一个name值等于“曹操”的文档数据,但是根据第二个搜索操作,address值等于“魏国”的全文搜索竟然搜索出了“蜀国”等文档数据。导致出现这种情况的原因是,name字段为keyword类型,存储时没有被分词,搜索的时候也被当作一个完整的词去匹配;而address字段时text类型,存储时会进行分词处理,搜索的时候先对搜索的内容进行分词,再和文档数据(文档数据也会进行分词)进行匹配。对这两个字段进行分词的范例如下:
# 对索引库种name字段的内容“Talk is cheap. Show me the code”进行分词
GET myindex/_analyze
{
"field": "name",
"text": "Talk is cheap. Show me the code"
}分词后的结果如下:
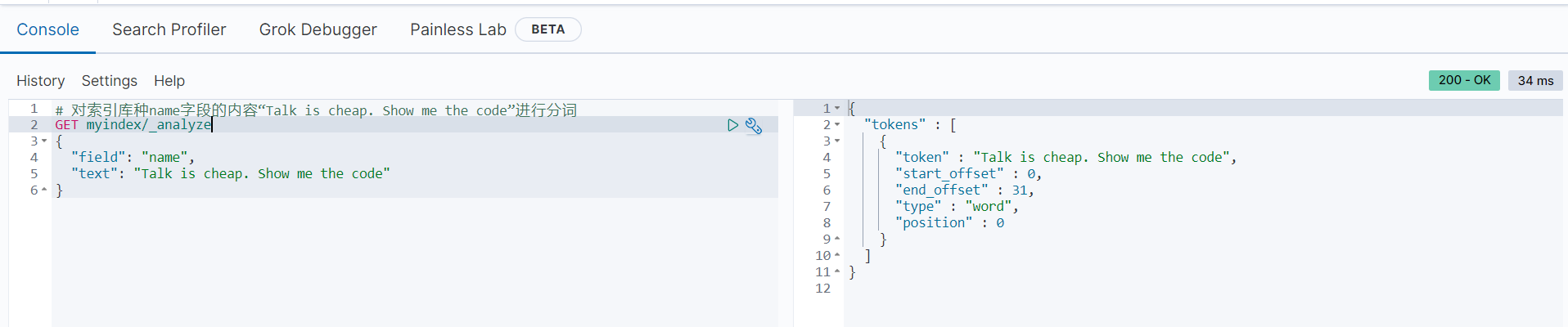
此结果与我们预知的一样,当前内容被当作一个完整的语句。下面对同样的内容使用address字段进行分析:
GET myindex/_analyze
{
"field": "address",
"text": "Talk is cheap. Show me the code"
}分词后的结果如下:
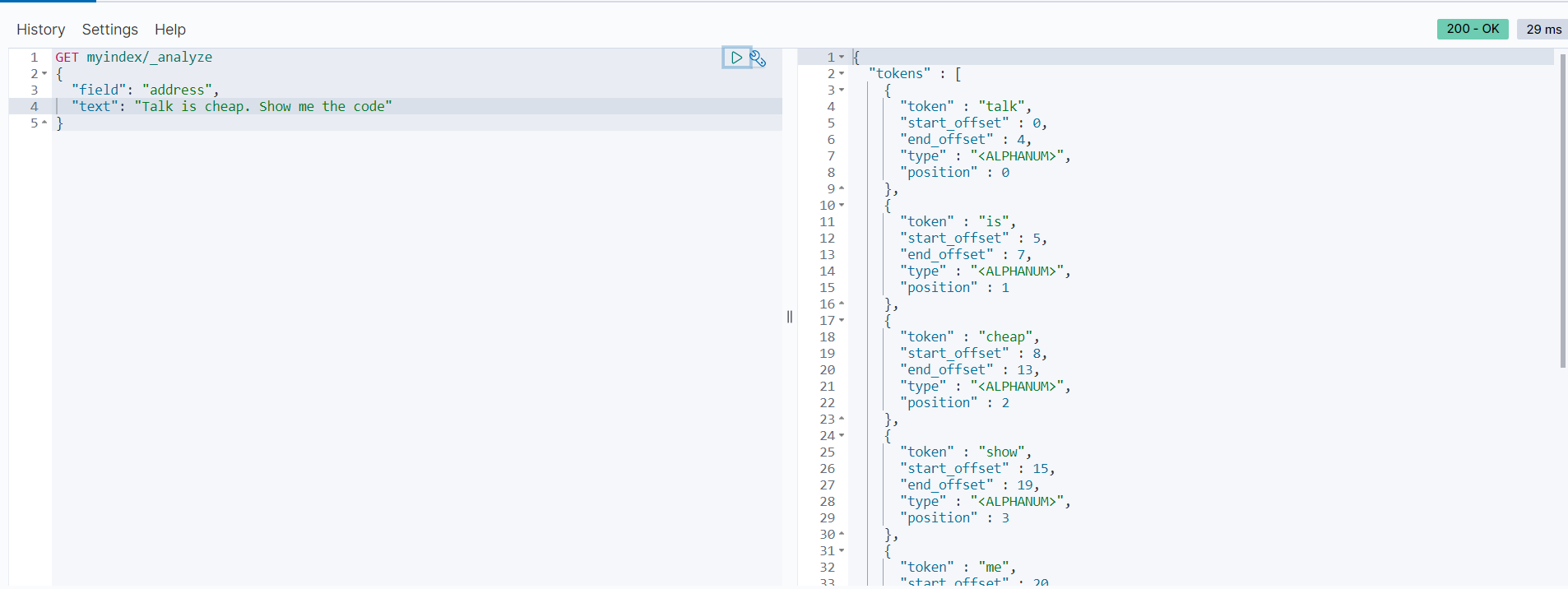
以上返回结果将“Talk is cheap. Show me the code”分成了单独的7个词。
因此我们在定义字段类型时,需要特别注意keyword类型与text类型的区别,因为二者会带来不同的结果。

Golang控制协程(goroutine)的并发数量
4/17/2025减小Go代码编译后的二进制体积
4/17/2025
Rust Match全模式列表
1/9/2025
Redis哨兵细节分析
12/12/2024