Elasticsearch分词器(三)IK分词器

前面的范例创建索引、搜索数据时都是使用默认的分词器,因为存储的都是中文,所以分词效果不太理想,会把text的字段分成一个个汉字,为了更好地对中文内容进行分词,需要更加智能的IK分词器。
IK分词器的安装
首先在GitHub官网搜索elasticsearch-analysis-ik并下载,也可以直接前往下载地址下载。
下面介绍Docker环境下下安装IK分词器,Docker安装Elasticsearch请参考Docker安装Elasticsearch + Kibana一文,这里不做累述。
$ cd /data/docker/elasticsearch/plugins
$ mkdir ik
$ cd ik
$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.13.2/elasticsearch-analysis-ik-7.13.2.zip
$ unzip elasticsearch-analysis-ik-7.13.2.zip
$ docker restart es01
# 查看启动日志,检查加载IK分词器是否成功
$ docker logs es01 | grep analysis-ik若出现loaded plugin [analysis-ik]日志信息,则表示IK分词器加载成功。
IK分词器的测试
以下时未使用IK分词器的范例:
POST _analyze
{
"text": "时光流逝,我对你的爱却与日俱增"
}分词后的结果如下:
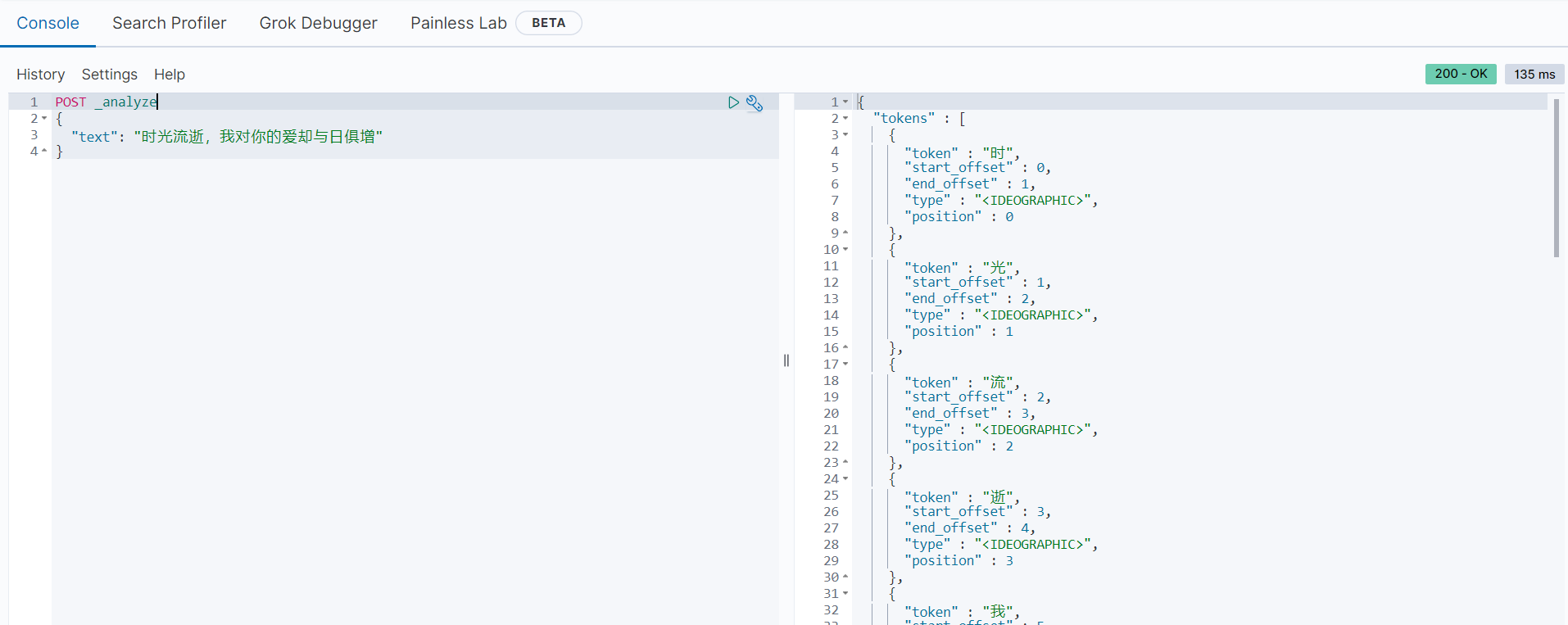
以上范例使用默认的分词器,会把中文内容分词成单独的汉字。下面来看使用IK分词器的范例:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "时光流逝,我对你的爱却与日俱增"
}分词后的结果如下:
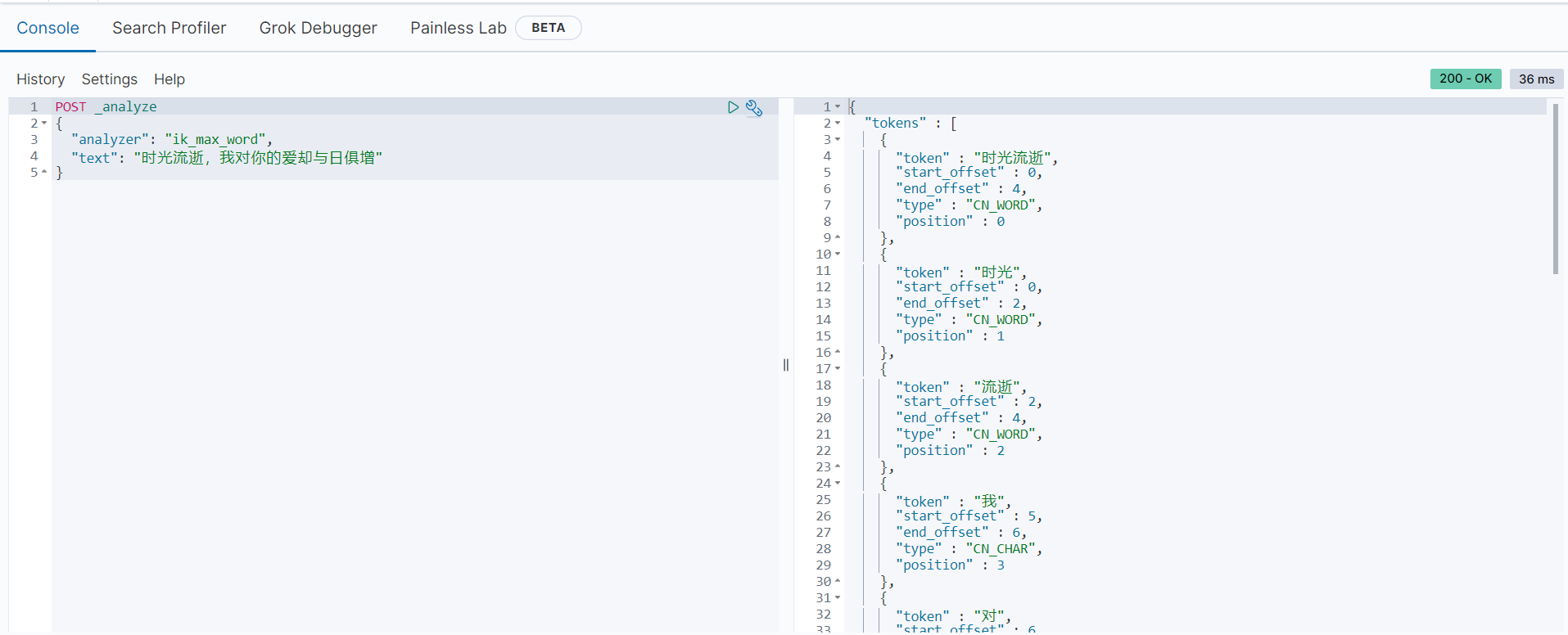
利用IK分词器,以上内容被分词为:
["时光流逝", "时光", "流逝", "我", "对", "你", "的", "爱", "却与", "与日俱增", "与日", "俱", "增"]值得注意的是:
IK分词器的两种分词模式
IK分词器有以下两种分词模型:
ik_max_word模式
-
范例一:对内容”有情人终成眷属“使用
ik_max_word分词模式POST _analyze { "analyzer": "ik_max_word", "text": "有情人终成眷属" }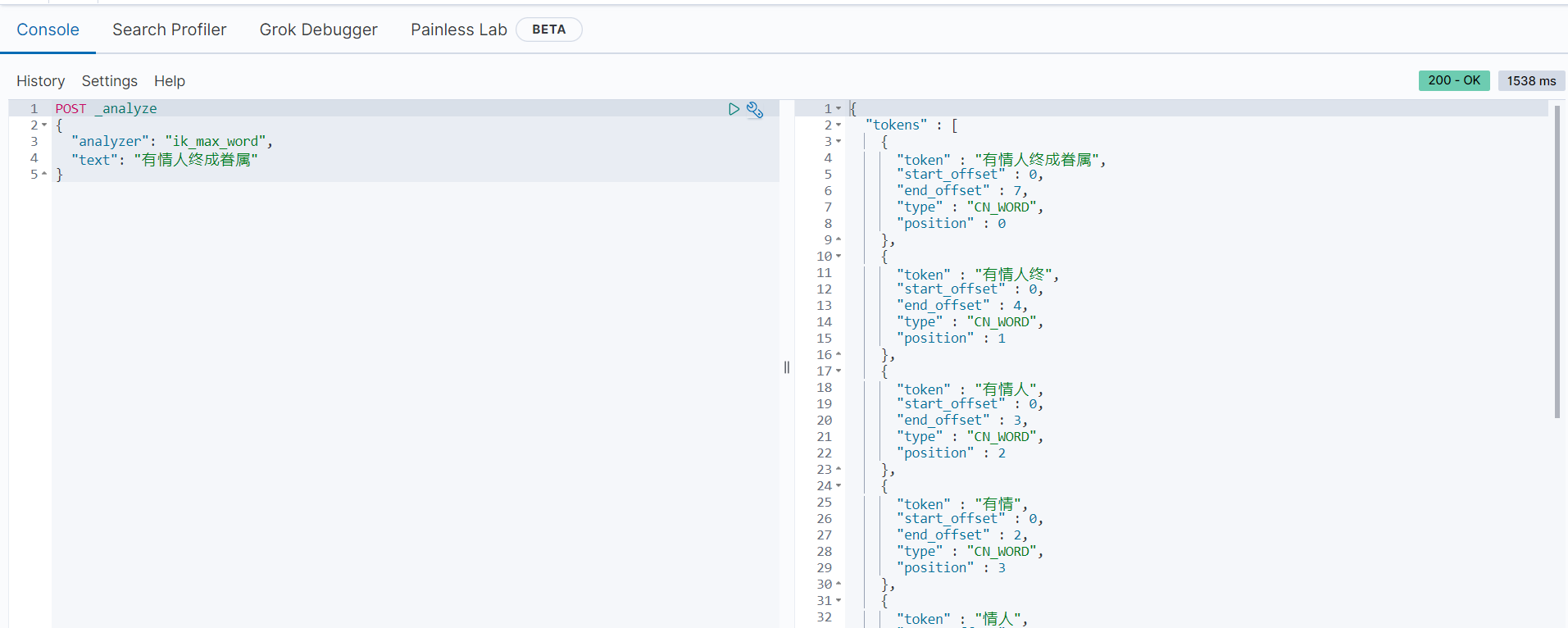 以上语句使用
以上语句使用ik_max_word模式将”有情人终成眷属“拆分为[有情人终成眷属, 有情人终, 有情人, 情人, 终成眷属, 眷属],产生了各种可能的组合,即不同的词。 -
范例二:对内容”失去了的东西永远不会再回来“使用
ik_max_word分词模式POST _analyze { "analyzer": "ik_max_word", "text": "失去了的东西永远不会再回来" }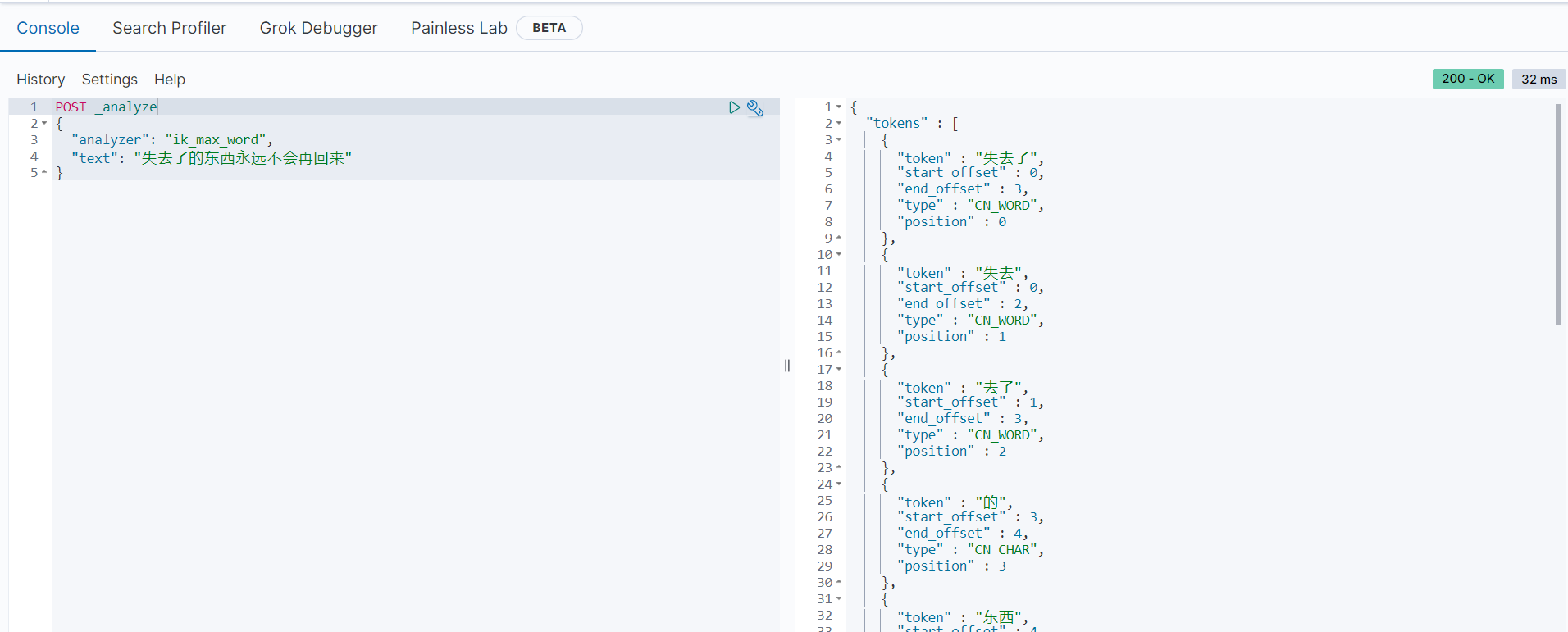 以上语句使用
以上语句使用ik_max_word模式将”失去了的东西永远不会再回来“拆分为[失去了, 失去, 去了, 的, 东西, 永远, 不会. 再回来, 再回, 回来],产生了各种可能的组合。
ik_smart模式
-
范例一:对内容”有情人终成眷属“使用
ik_smart分词模式POST _analyze { "analyzer": "ik_smart", "text": "有情人终成眷属" } 以上语句使用
以上语句使用ik_smart模式将”有情人终成眷属“拆分为[有情人终成眷属],产生了尽可能少的组合。 -
范例二:对内容”失去了的东西永远不会再回来“使用
ik_smart分词模式POST _analyze { "analyzer": "ik_smart", "text": "失去了的东西永远不会再回来" }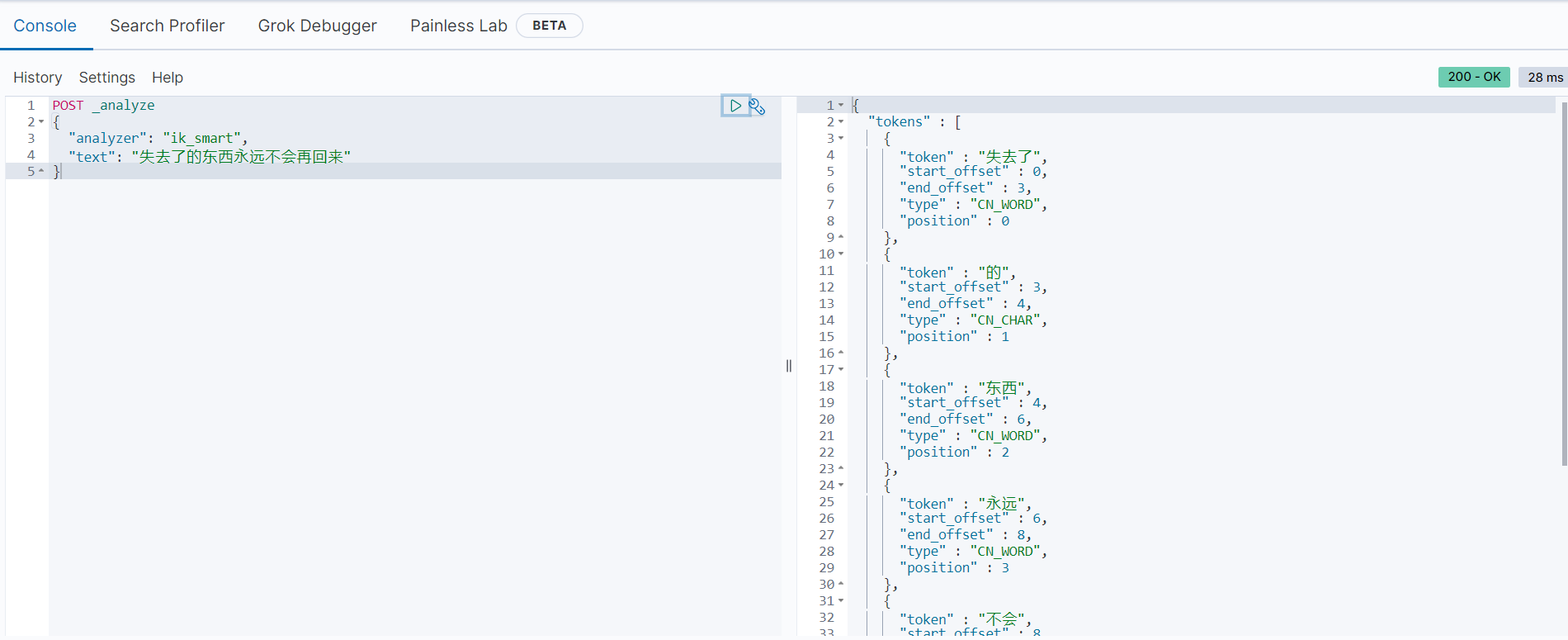 以上语句使用
以上语句使用ik_smart模式将”失去了的东西永远不会再回来“拆分为[失去了, 的, 东西, 永远, 不会, 再回来],产生尽可能少的组合。
创建使用IK分词器的索引映射
一般在创建索引时会明确指定分词的模式,总共有两种操作:一种是让所有text类型的字段都使用分词模式,另一种是给每一种text类型的字段指定分词模式。
下面的范例是所有text类型的字段都是用同一种分词模式:
# 创建索引模板,所有“text”类型的字段都使用IK分词器的“ik_max_word”模式
PUT myindex
{
"settings": {
"analysis": {
"ik": {
"tokenizer": "ik_max_word"
}
}
},
"mappings": {
"properties": {
"field1": {
"type": "text"
}
}
}
}下面的范例为每一个text类型字段分别指定特定的分词模式:
PUT myindex
{
"mappings": {
"properties": {
"field1": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"field2": {
"type": "text",
"analyzer": "standard",
"search_analyzer": "standard"
},
"field3": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}由以上语句可知,field1字段使用ik_max_word分词模式,field2字段使用默认的standard分词模式,field3字段使用IK分词器的ik_smart模式。
下面的范例存储和搜索使用不同的分词模式:
# 创建索引映射,存储时使用IK分词器的ik_max_word模式,搜索时使用IK分词器的ik_smart模式
PUT myindex
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"age": {
"type": "integer"
}
}
}
}
# 插入文档数据
POST myindex/_doc
{
"name": "曹操",
"address": "魏国",
"age": 18
}
# 插入文档数据
POST myindex/_doc
{
"name": "张辽",
"address": "魏国",
"age": 19
}
# 插入文档数据
POST myindex/_doc
{
"name": "刘备",
"address": "蜀国",
"age": 30
}
# 插入文档数据
POST myindex/_doc
{
"name": "姜维",
"address": ["魏国", "蜀国"],
"age": 20
}
POST myindex/_doc
{
"name": "孙十万",
"address": "吴国",
"age": 35
}
# 全文搜索address等于“魏国”的数据
GET myindex/_search
{
"query": {
"match": {
"address": "魏国"
}
}
}返回结果如下:
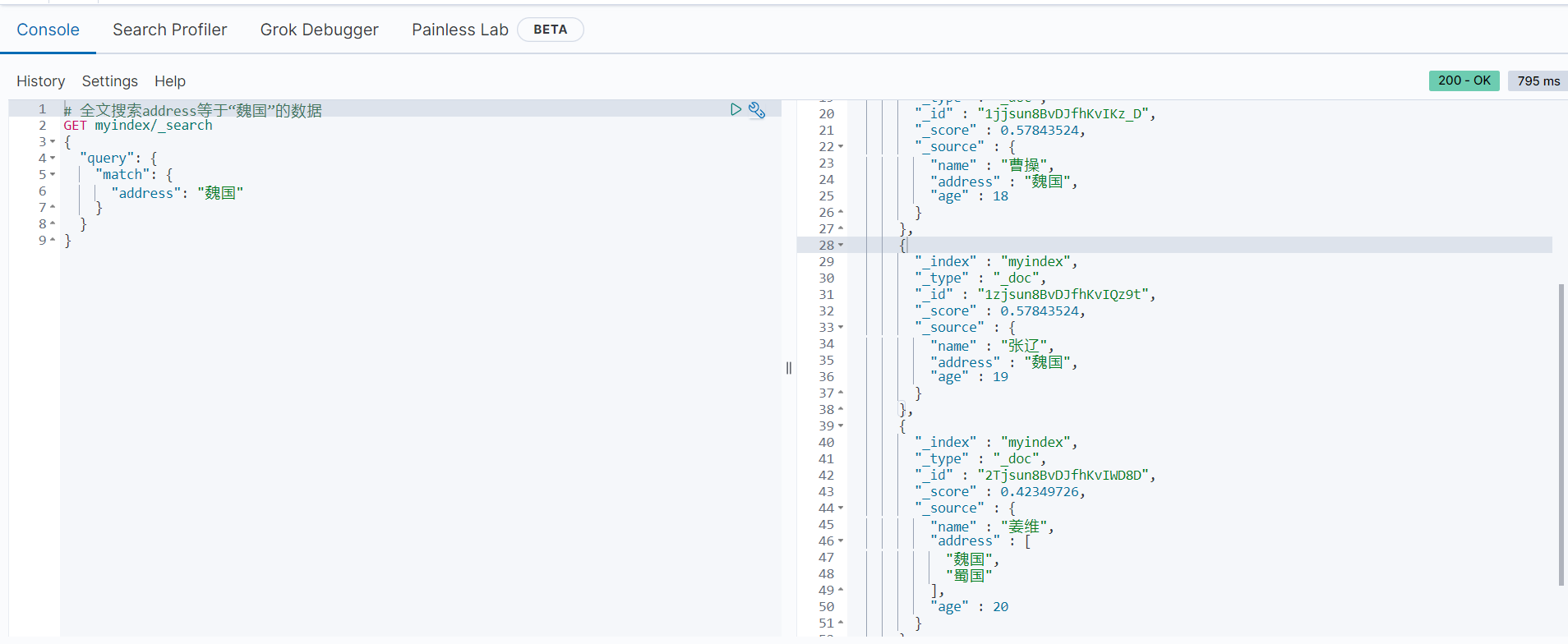
可以看到,返回的结果都符合我们的预期。
下面的语句将使用最细粒度的搜索:
GET myindex/_search
{
"query": {
"match": {
"address": {
"query": "魏国",
"analyzer": "ik_smart"
}
}
}
}需要注意的是,因为我们在设置映射模板的时使用最细粒度进行分词存储(分词尽可能多),所以在搜索时可以指定对最细粒度的分词模式和最粗粒度的分词模式分别搜索。在正式项目的使用中也推荐这种做法,存储时选择尽量细的分词规则,这样在搜索时可以指定符合具体项目要求的分词模式。

Golang控制协程(goroutine)的并发数量
4/17/2025减小Go代码编译后的二进制体积
4/17/2025
Rust Match全模式列表
1/9/2025
Redis哨兵细节分析
12/12/2024