Elasticsearch Term级别查询
Elasticsearch的term级别查询详解
本文将讲解Elasticsearch中的各种term级别查询,如exists、ids等查询,以及通配符和范围查询。
在开始前,首先准备一下数据:
PUT /myindex-term-level
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"clubs": {
"type": "keyword"
},
"age": {
"type": "long"
}
}
}
}
POST /myindex-term-level/_bulk
{ "index": {"_id": 1} }
{ "name": "Messi", "clubs": ["FC Barcelona", "Paris SG"], "age": 35, "position": "Right Winger" }
{ "index": { "_id": 2 } }
{ "name": "Iniesta", "clubs": ["FC Barcelona", "Vissel Kobe"], "age": 38, "position": "Central Midfield" }
{ "index": { "_id": 3 } }
{ "name": "Thiago", "clubs": ["FC Barcelona", "Bayern Munich", "Liverpool FC"], "age": 31 }
{ "index": { "_id": 4 } }
{ "name": "Alex Oxlade-Chamberlain", "clubs": ["Southampton FC", "Arsenal FC", "Liverpool FC"], "age": 29 }
exists查询
在Elasticsearch中可以使用exists进行查询,判断文档中是否存在对应字段。范例如下:
# 查询索引库中存在position字段的文档数据
GET /myindex-term-level/_search
{
"query": {
"exists": {
"field": "position"
}
}
}
返回结果如下:
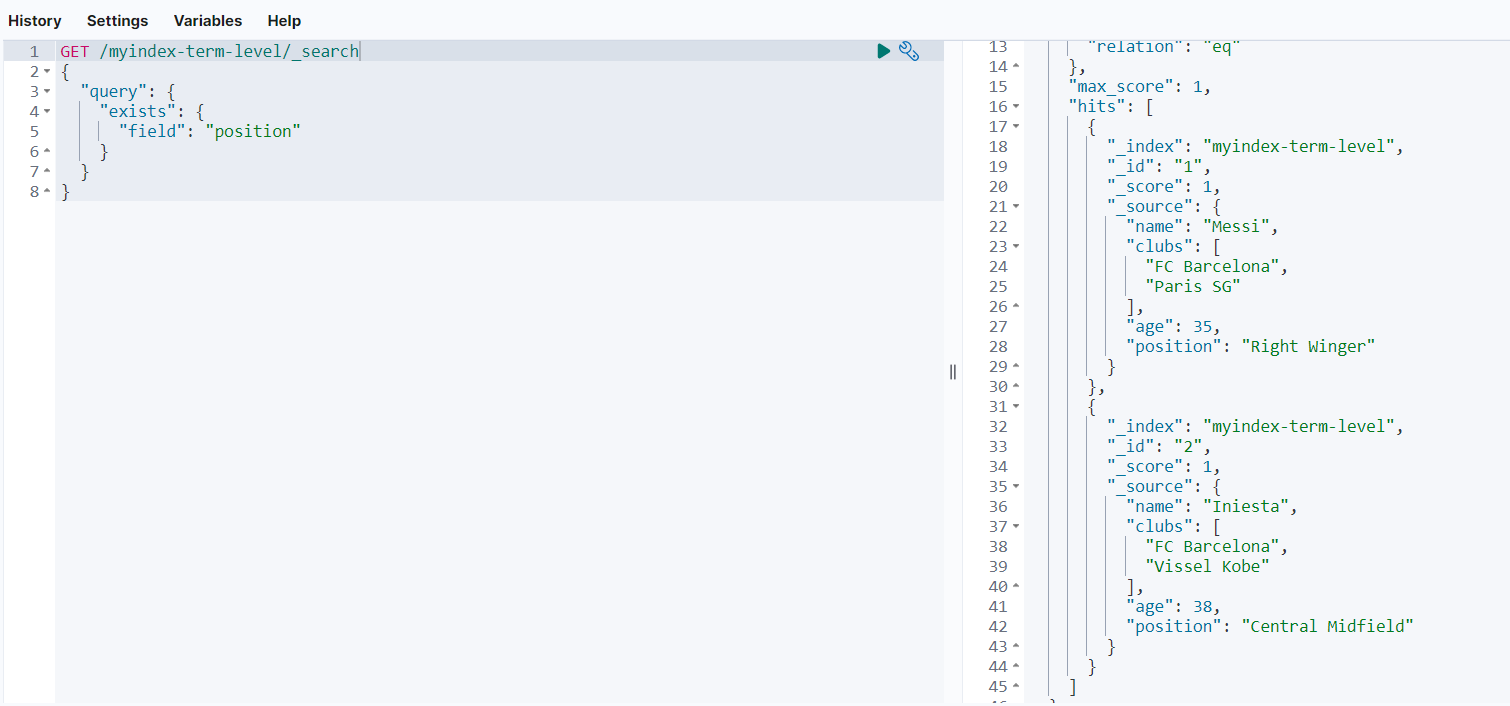
可以看到,只返回了_id等于1和2的文档数据,因为只有这两个文档存在position字段。
ids查询
通过id进行批量查询。形如SQL中的select * from table where id in (1, 2, 3)。范例如下:
GET /myindex-term-level/_search
{
"query": {
"ids": {
"values": [2, 1]
}
}
}
返回结果如下:
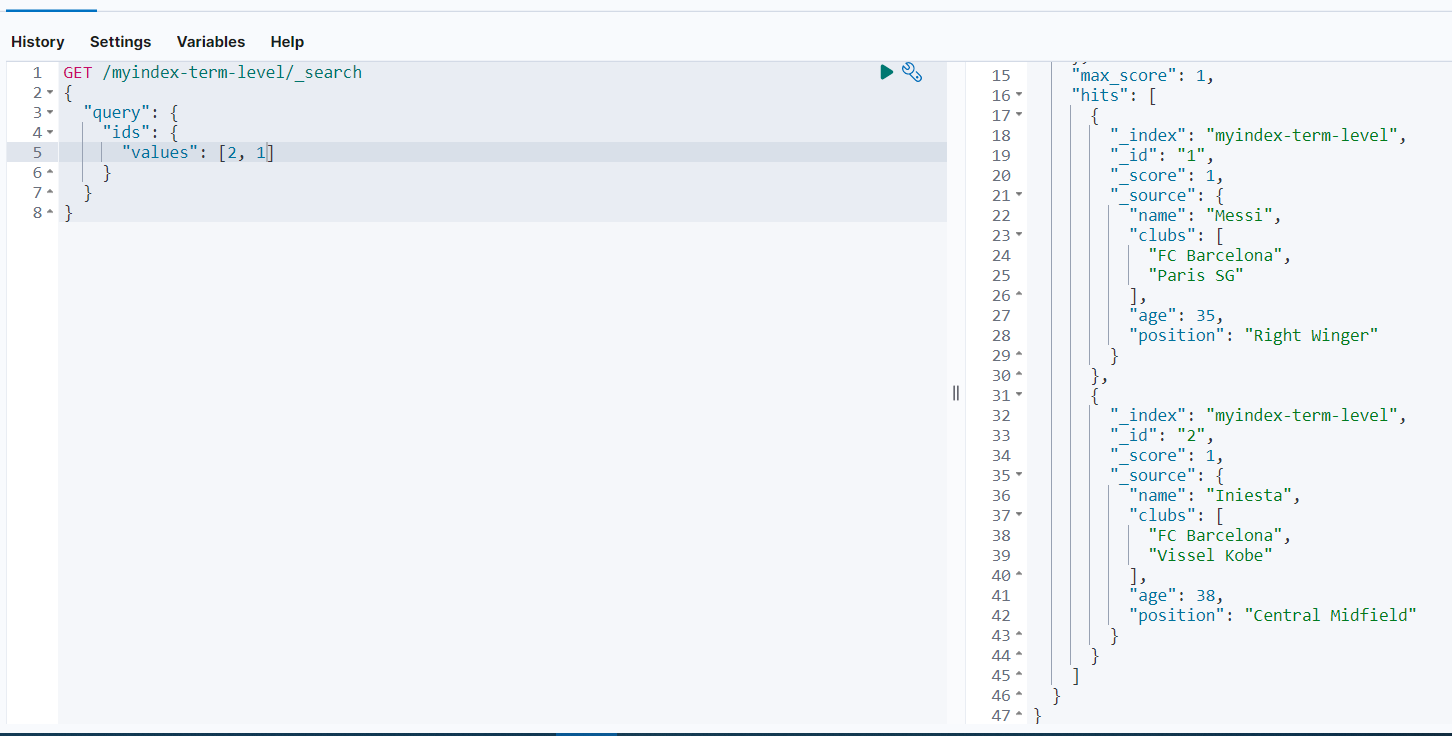
可以看到结果只返回了_id等于1和2的文档数据。同时我们也可以看出,返回结果的顺序和我们查找是设置的顺序没有任何关系。
prefix查询
在Elasticsearch中,使用prefix可以根据前缀来查找某个字段。范例如下:
GET /myindex-term-level/_search
{
"query": {
"prefix": {
"name": {
"value": "Me"
}
}
}
}
查询结果如下:
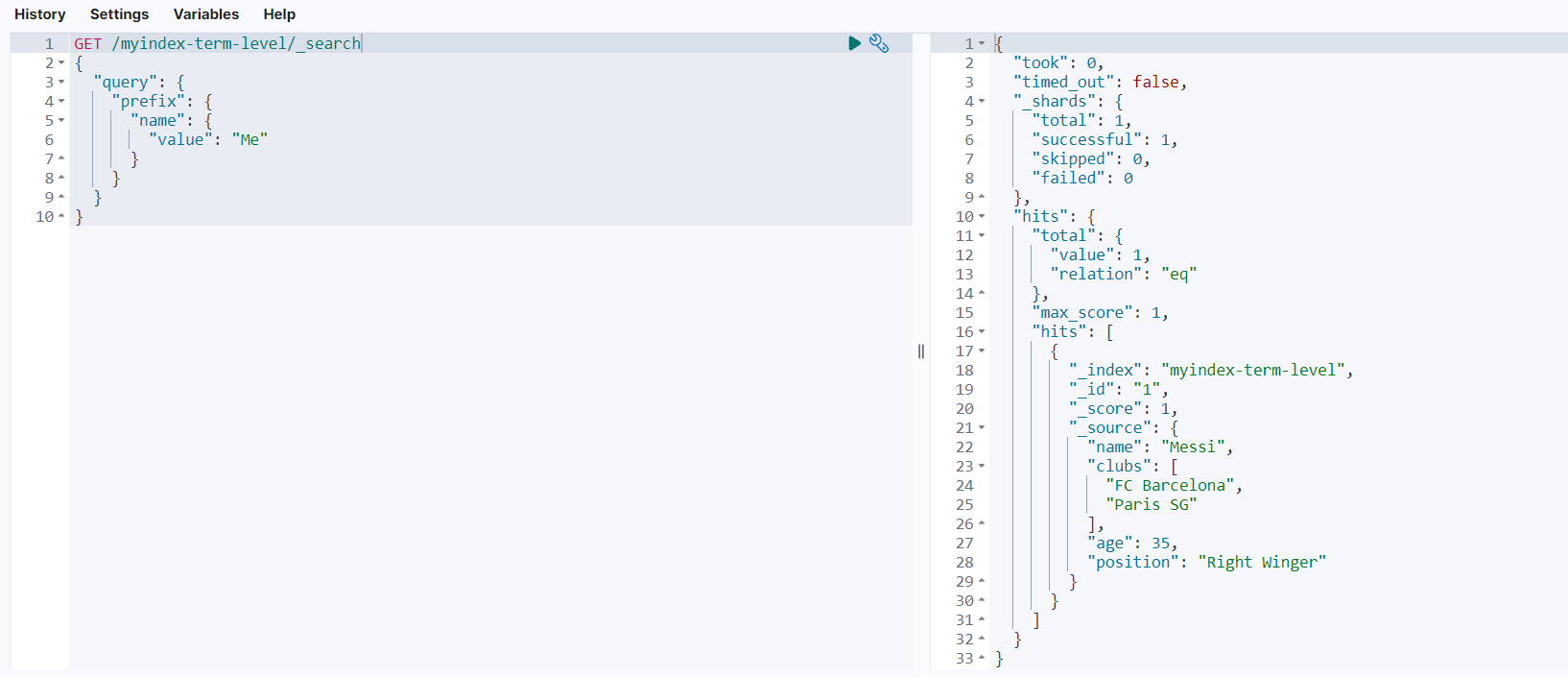
term查询
term查询是结构化精准查询的主要查询方式,用于查询待查字段和查询值是否完全匹配,其请求形式如下:
GET /${index_name}/_search
{
"query": {
"term": {
"${FIELD}": { // 搜索字段名称
"value": "${VALUE}" // 搜索值
}
}
}
}
示例如下:
GET /myindex-term-level/_search
{
"query": {
"term": {
"clubs": "FC Barcelona"
}
}
}
返回结果如下:
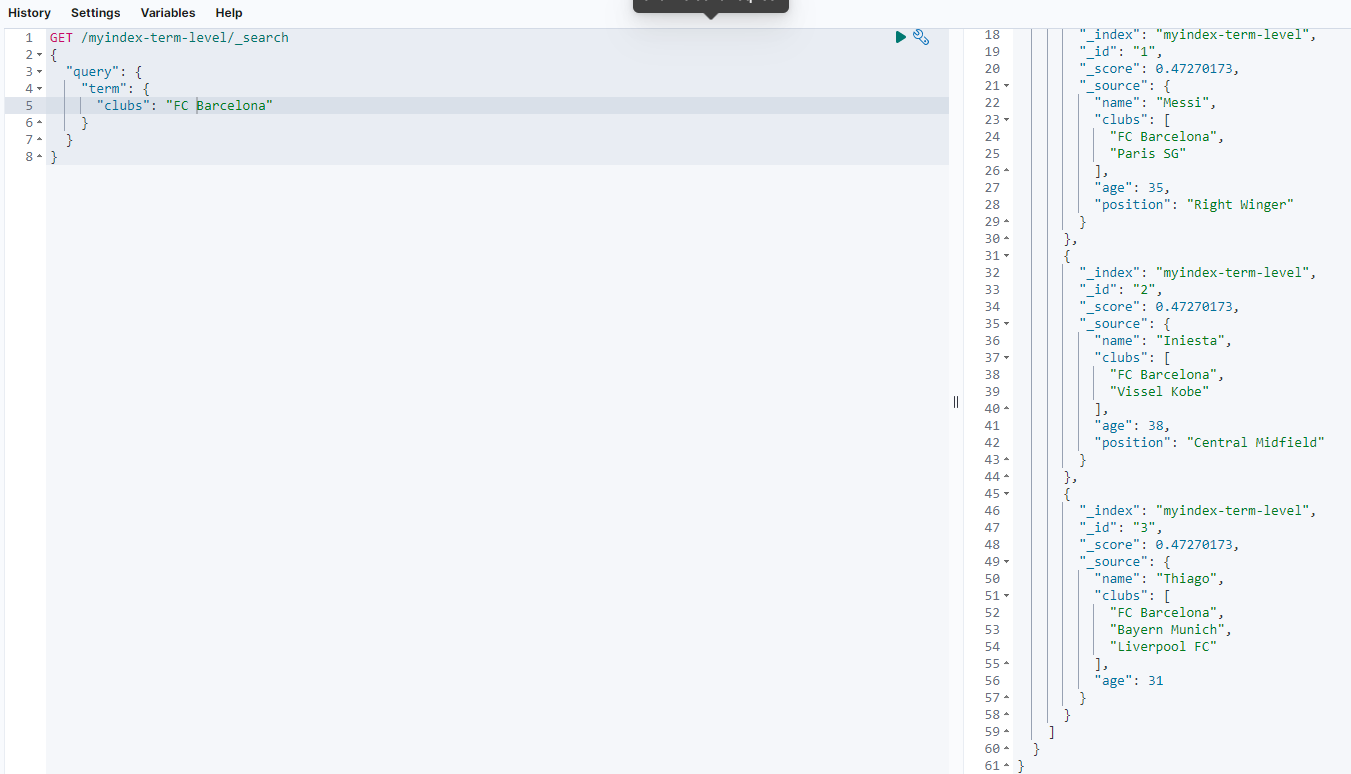
可以看到,_id分别等于1、2、3的文档信息中clubs字段的内容都包含FC Barcelona,符合查询要求。
terms查询
terms查询是term查询的扩展形式,用于查询一个或多个值与待查字段是否完全匹配,其请求形式如下:
GET /${index_name}/_search
{
"query": {
"terms": {
"FIELD": [ // 指定查询字段
"VALUE1", // 指定查询值
"VALUE2"
]
}
}
}
范例如下:
GET /myindex-term-level/_search
{
"query": {
"terms": {
"clubs": ["Bayern Munich", "Vissel Kobe"]
}
}
}
查询结果如下:
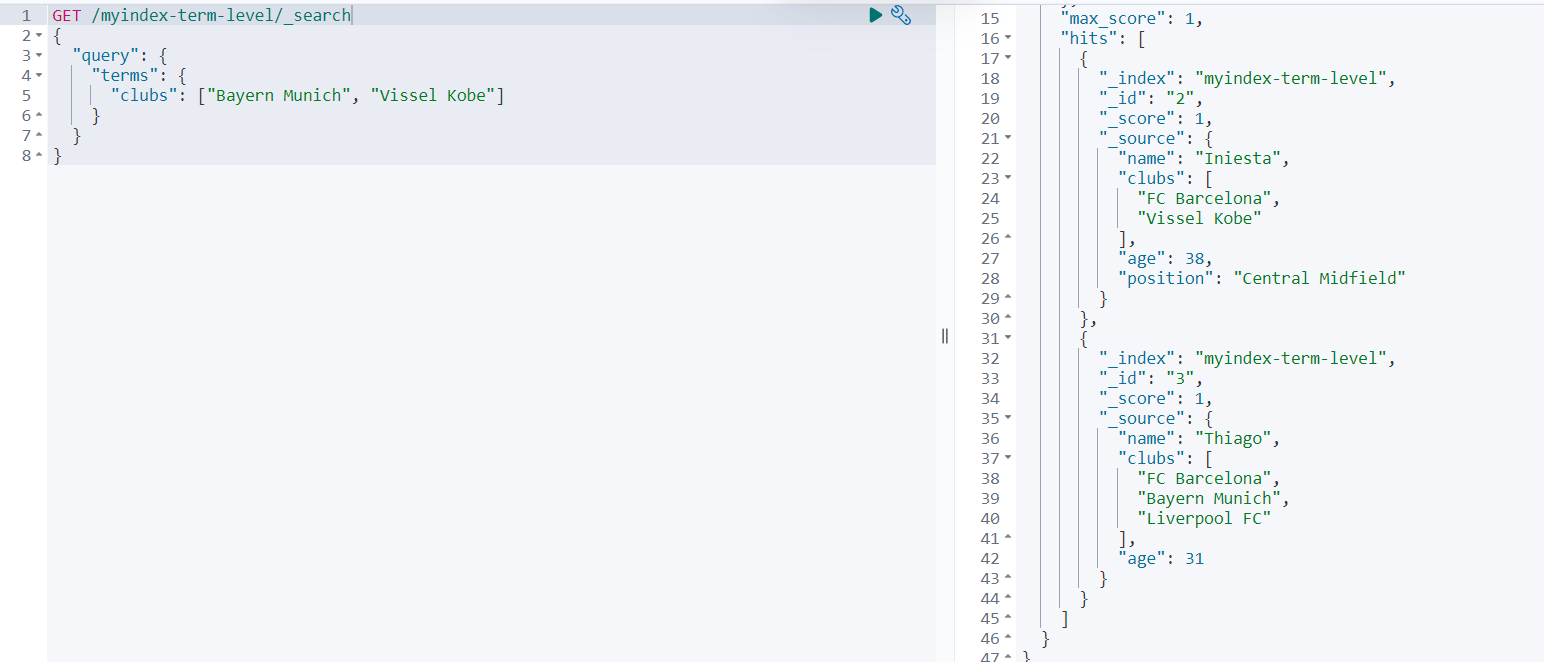
可以看到,总共返回了2条文档数据,这些内容不是查询到Bayern Munich,就是查询到 Vissel Kobe。
terms_set查询
使用terms_set关键字查询可以统计文档中动态匹配到单词的个数。
组装数据:
PUT /job-candidates
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"programming_languages": {
"type": "keyword"
},
"required_matches": {
"type": "long"
}
}
}
}
PUT /job-candidates/_doc/1?refresh
{
"name": "Jane Smith",
"programming_languages": [ "c++", "java" ],
"required_matches": 2
}
PUT /job-candidates/_doc/2?refresh
{
"name": "Jason Response",
"programming_languages": [ "c++", "java", "php" ],
"required_matches": 3
}
范例一:查询programming_languages字段的内容匹配到c++和java,而最少匹配到的单词数量存储在当前文档中的required_matches字段中:
GET /job-candidates/_search
{
"query": {
"terms_set": {
"programming_languages": {
"terms": [ "c++", "java" ],
"minimum_should_match_field": "required_matches"
}
}
}
}
返回结果如下:
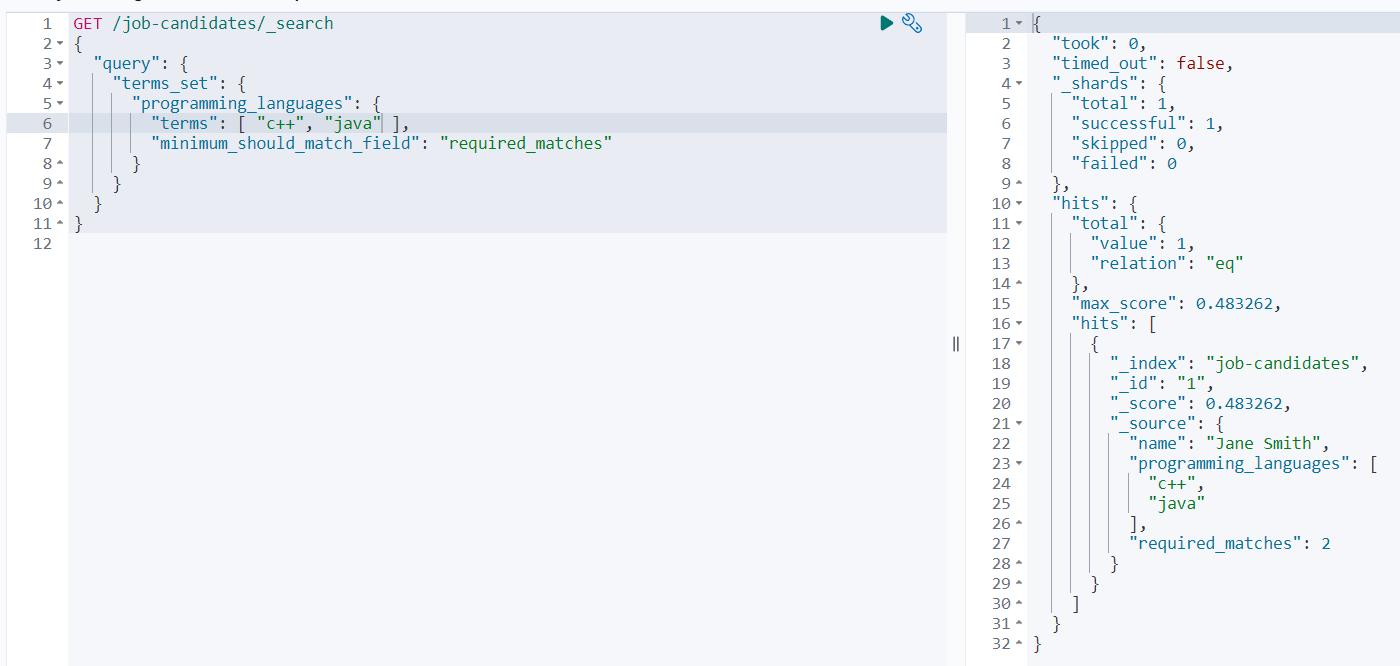
通配符查询
在Elasticsearch中,如果需要通过通配符进行查询,可使用wildcard来进行处理。范例如下:
GET /myindex-term-level/_search
{
"query": {
"wildcard": {
"clubs": {
"value": "FC*"
}
}
}
}
返回结果如下:
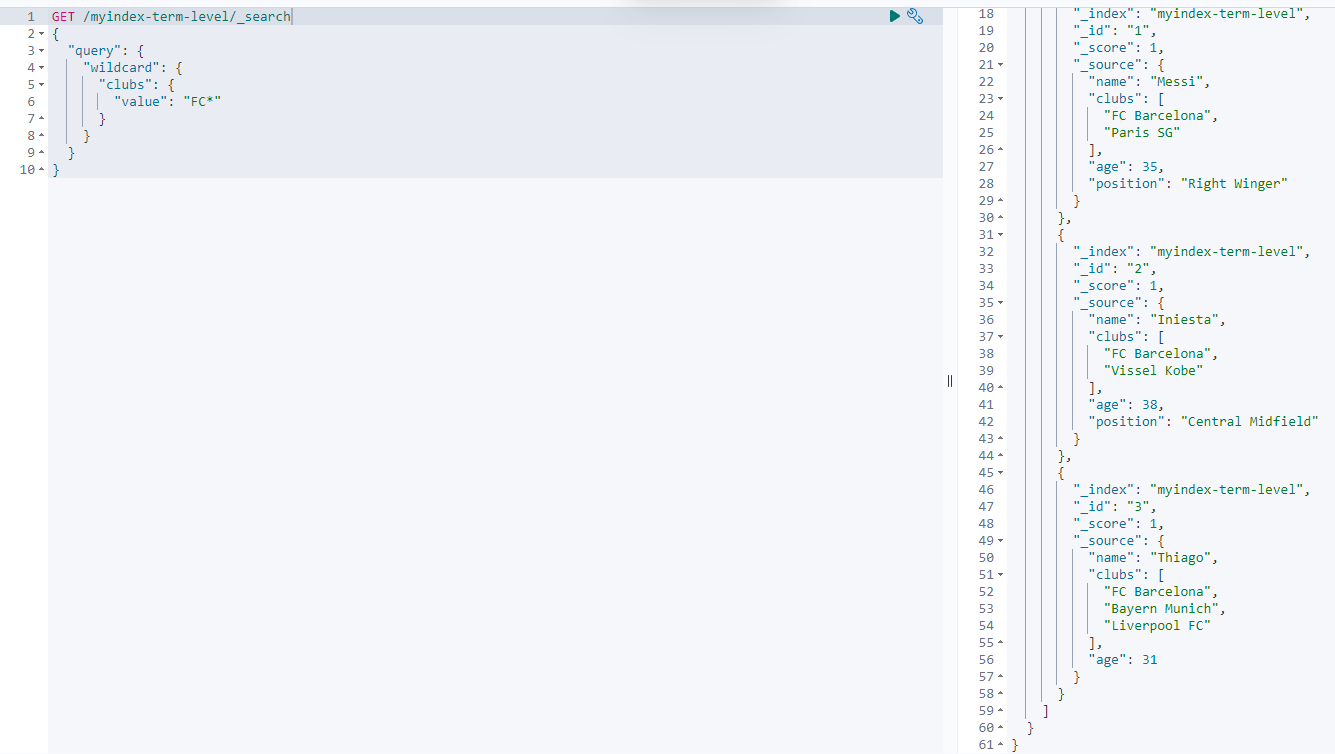
range查询
range查询用于范围查询,一般是对数值型和日期型数据的查询。使用range进行范围查询时,用户可以按照需求中是否包含边界数值进行选项设置,可供组合的选项如下:
范例如下:
GET /myindex-term-level/_search
{
"query": {
"range": {
"age": {
"gt": "35"
}
}
}
}
返回结果如下:
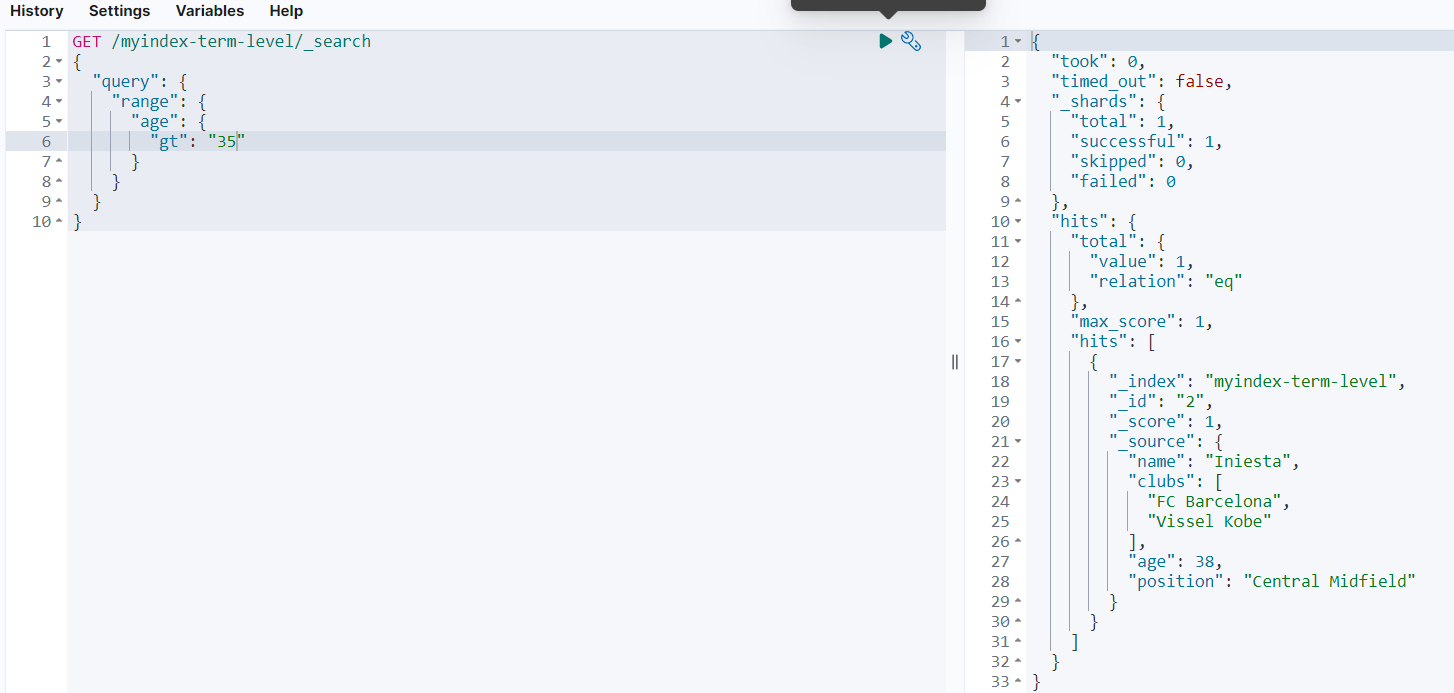
fuzzy查询(模糊匹配)
返回包含与搜索词相似的词的文档(将一个词转换为另一个词)。这些变化可以包括:
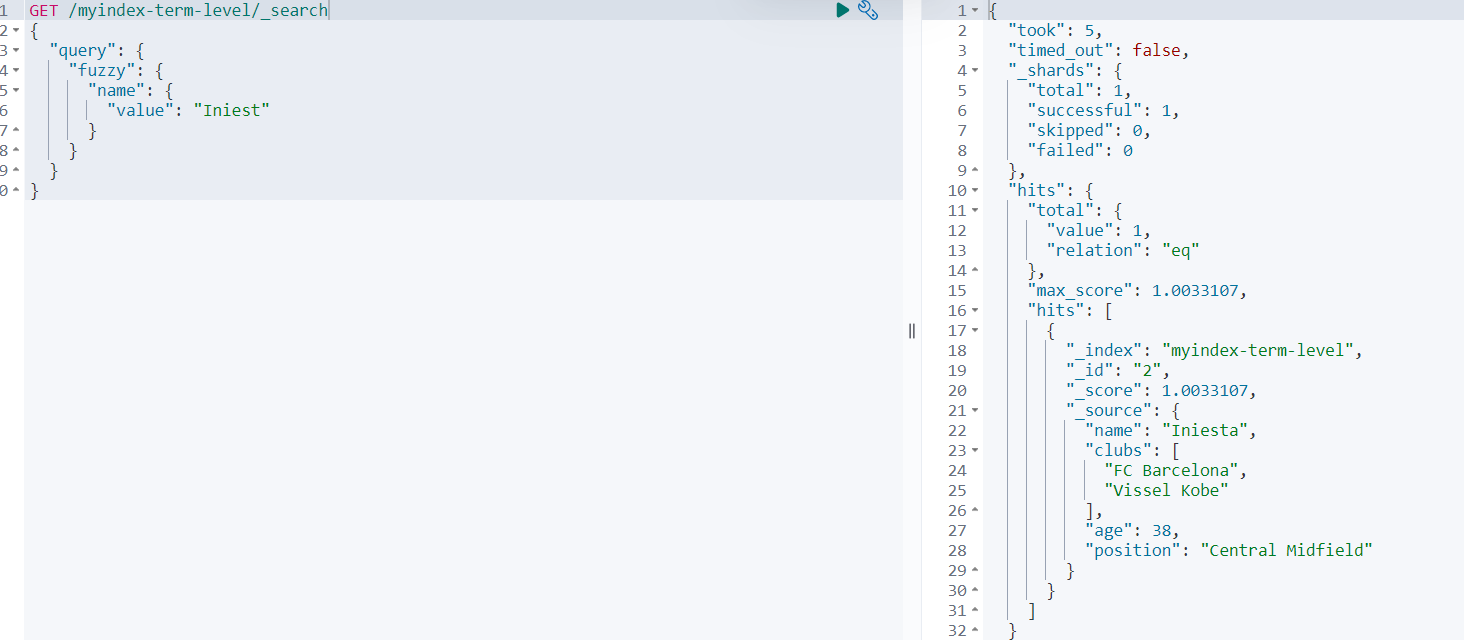
范例如下:
GET /myindex-term-level/_search
{
"query": {
"fuzzy": {
"name": {
"value": "Iniest"
}
}
}
}
查询结果如下:
正则表达式查询
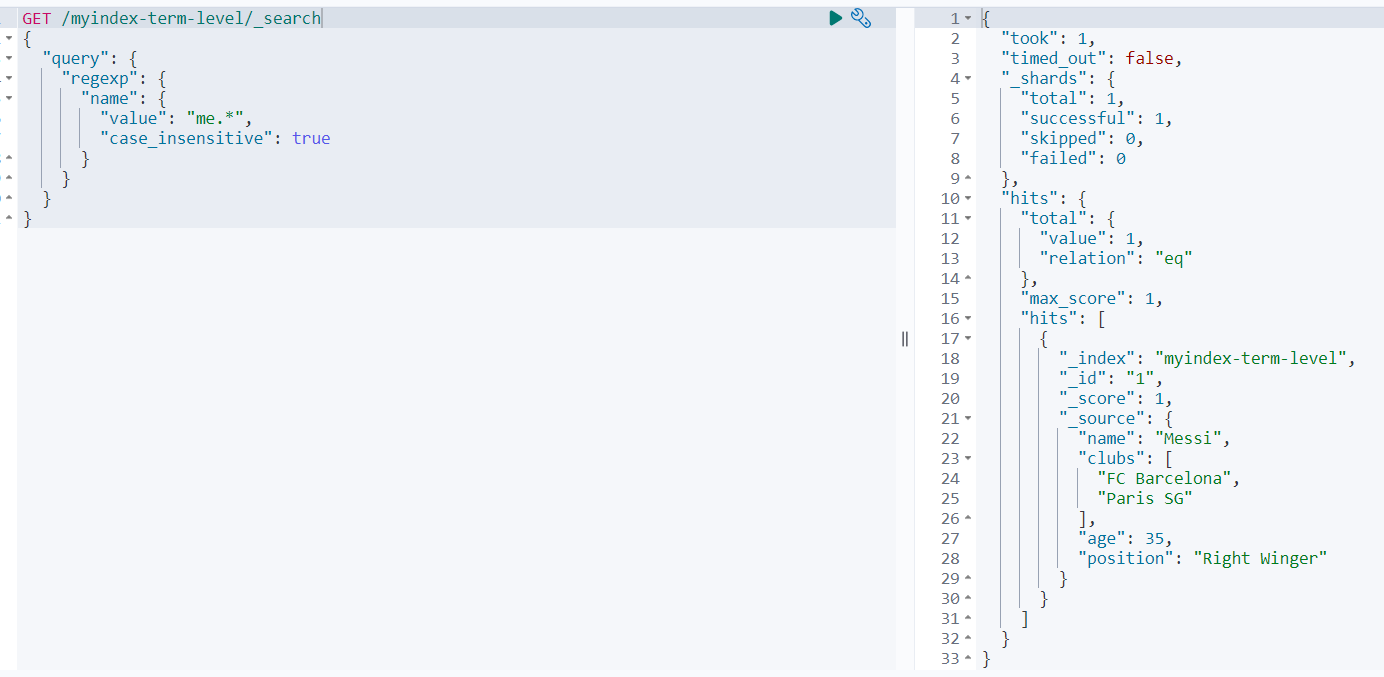
范例如下:
GET /myindex-term-level/_search
{
"query": {
"regexp": {
"name": {
"value": "me.*",
"case_insensitive": true
}
}
}
}
查询结果如下:
正则表达式的一些参数说明如下:


